开放存储(Storage API)介绍
为了更好地融入大数据生态,并支持外部引擎访问MaxCompute中的数据,MaxCompute提供了开放存储(Storage API)。第三方主流计算引擎可通过调用Storage API直接访问MaxCompute的底层存储,从而显著提升数据访问和交互效率(本功能处于公测阶段)。
MaxCompute查询加速 MaxQA
本文为您介绍MaxCompute查询加速 MaxQA引擎(MaxCompute Query Accelerator 2.0)功能,并帮助您了解该功能的系统架构、应用场景、使用限制和使用方法。
镜像管理
MaxCompute提供镜像管理功能,内置数据分析、科学计算、机器学习(如Pandas、Numpy、Scikit-learn、Xgboost)等各类常用镜像,并已对镜像进行预先加热,同时支持上传自定义镜像,您可在SQL UDF、PyODPS及MaxFrame开发等场景中直接引用已有镜像,无需执行繁琐的资源打包、上传等流程。
增量计算概述
MaxCompute增量计算是基于Delta Table增量数据存储和读写能力,通过CDC能力扩展增量物化视图,Time travel 以及 Stream Table 等一系列的增量计算能力。同时增量物化视图(IMV)和周期性调度任务提供了不同的触发频率,从而为用户提供更多手段来平衡延迟(Latency)和吞吐量(Throughput)。
Go SDK概述
Go SDK是MaxCompute提供的一套Go编程语言接口,您可以通过该接口使用Go代码来操作和管理MaxCompute服务,例如访问和管理项目、操作数据表和数据传输等。
Hadoop生态系统概述:构建大数据处理与分析的基石
在当今的大数据时代,Hadoop作为开源的大数据处理框架,已经成为众多企业和组织处理大规模数据集的首选工具。Hadoop生态系统是一个由多个组件组成的复杂系统,旨在提供全面的数据存储、处理和分析能力。本文将深入探讨Hadoop生态系统的核心组件、工作原理、应用场景以及其优势和局限性。 Hadoop生态系统的核心组件 Hadoop Distributed ...
Hadoop 概述、Hadoop 发展历史、Hadoop 三大发行版本、Hadoop优势、Hadoop组成、Hadoop1.x、2.x、3.x区别、HDFS架构概述、大数据技术生态体系、推荐系统框架图
1.Hadoop 概述1.1Hadoop 是什么1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 2)主要解决,海量数据的存储和海量数据的分析计算问题。 3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。1.2Hadoop 发展历史(了解)1)Hadoop创始人Doug Cutting,为了实现与Google类似的全文搜索功能,他在Lucene框架....
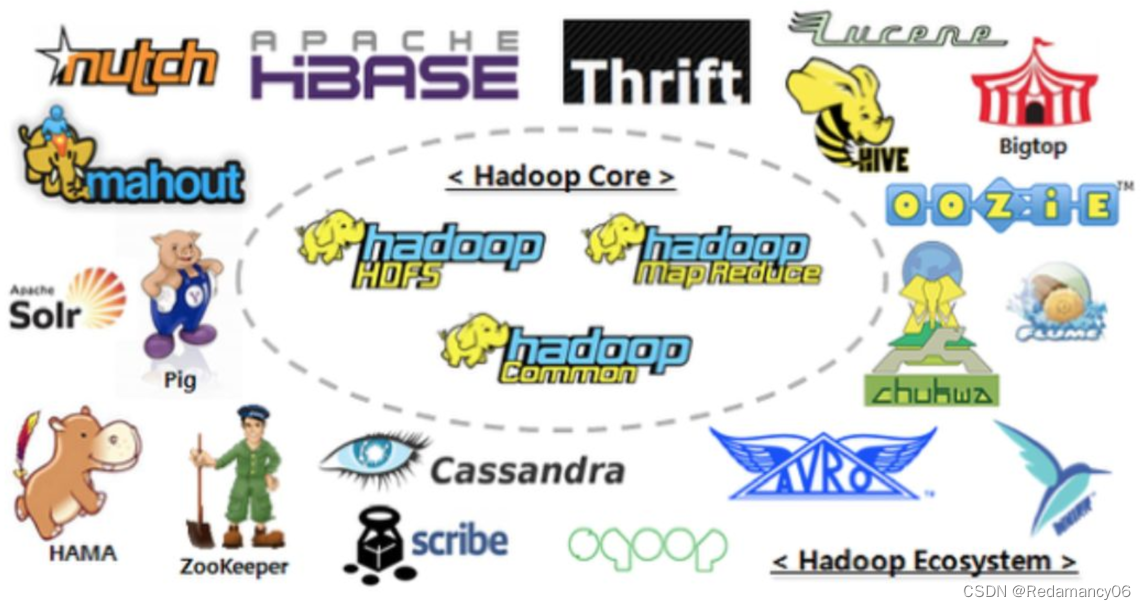
Hadoop 概述、Hadoop 发展历史、Hadoop 三大发行版本、Hadoop优势、Hadoop组成、Hadoop1.x、2.x、3.x区别、HDFS架构概述、大数据技术生态体系、推荐系统框架图
1.Hadoop 概述1.1Hadoop 是什么1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 2)主要解决,海量数据的存储和海量数据的分析计算问题。 3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。1.2Hadoop 发展历史(了解)1)Hadoop创始人Doug Cutting,为了实现与Google类似的全文搜索功能,他在Lucene框架....
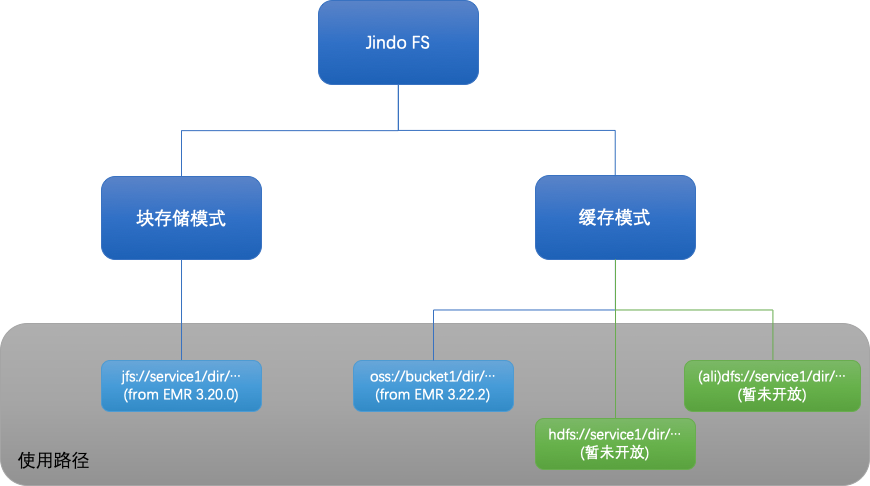
JindoFS概述:云原生的大数据计算存储分离方案
作者:诚历,阿里巴巴计算平台事业部 EMR 技术专家,Apache Sentry PMC,Apache Commons Committer,目前从事开源大数据存储和优化方面的工作。 JindoFS概述:云原生的大数据计算存储分离方案 JindoFS 之前 在 JindoFS 之前,云上客户主要使用 HDFS 和 OSS/S3 作为大数据存储。HDFS 是 Hadoop 原生的存储系统,10 年.....
Spark入门,概述,部署,以及学习(Spark是一种快速、通用、可扩展的大数据分析引擎)
1:Spark的官方网址:http://spark.apache.org/ 1 Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute解析
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute操控
- 云原生大数据计算服务 MaxCompute工具
- 云原生大数据计算服务 MaxCompute较量
- 云原生大数据计算服务 MaxCompute温度
- 云原生大数据计算服务 MaxCompute数据链路
- 云原生大数据计算服务 MaxCompute预测性维护
- 云原生大数据计算服务 MaxCompute故障
- 云原生大数据计算服务 MaxCompute设备
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
