
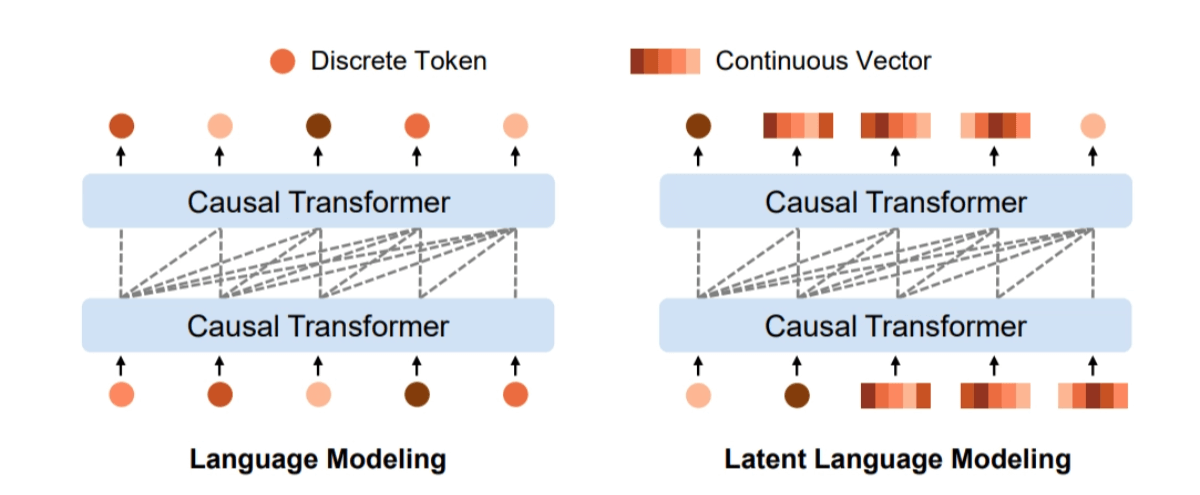
LatentLM:微软联合清华大学推出的多模态生成模型,能够统一处理和生成图像、文本、音频和语音合成
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦! 微信公众号|搜一搜:蚝油菜花 快速阅读 多模态处理:LatentLM能同时处理离散和连续数据,如文本、图像、音频等。 自回归生成:基于next-token diffusion技术,模型自回归生成连续数据的潜在向量。 ...
微软NaturalSpeech语音合成推出第三代
微软近期推出了NaturalSpeech语音合成技术的第三代产品——NaturalSpeech 3,这是其在自然语音合成领域的又一重要里程碑。这一全新的文本到语音(TTS)系统,采用了创新的因子化扩散模型,能够在没有任何先前样本的情况下,生成自然且高质量的语音。这一技术的进步不仅展示了微软在语音合成技术上的领先地位,也为未来的语音交互和智能助手的发展提供了更多可能性。 NaturalSpeec.....

黄学东:微软TTS,第一款实时神经网络语音合成服务
一个月之前,微软发布了基于深度神经网络的文本到语音(text-to-speech,TTS)系统,并且做为 Azure 认知服务中的一项,提供面向客户的预览版本。就此,我们采访了微软语音、自然语言与机器翻译的技术负责人黄学东,他向我们展示了一系列 TTS 生成的「真假难辨」的语音样例,并分享了微软在 TTS 一途上的经历与考量。下面的视频里包括了三段录音与三段合成音,你能分辨出机器与人声的区别吗?....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
