
内网桌面监控软件深度解析:基于 Python 实现的 K-Means 算法研究
在企业内部网络管理体系中,内网桌面监控软件扮演着至关重要的角色。其通过实时监测员工桌面操作,为企业信息安全提供有力保障,并对工作效率的提升具有显著作用。这些常规监控功能的背后,实则蕴含着复杂的数据结构与算法体系。本文将深入探究 K-Means 聚类算法,剖析其于内网桌面监控软件中的应用原理,并运用 Python 语言实现该算法。 ...

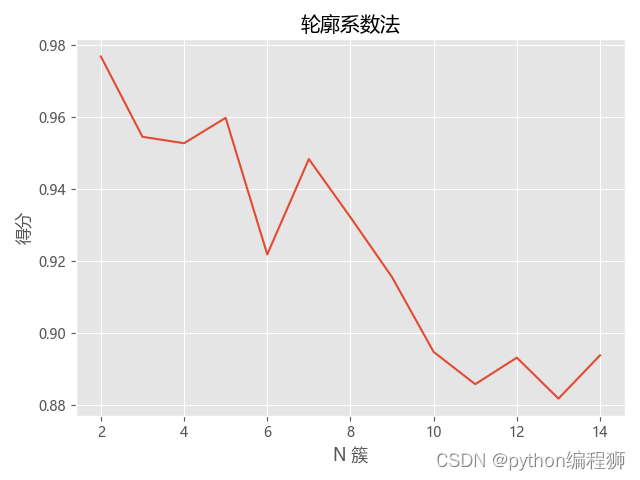
基于python的k-means聚类分析算法,对文本、数据等进行聚类,有轮廓系数和手肘法检验
K-means算法是一种常见的聚类算法,用于将数据点分成不同的组(簇),使同一组内的数据点彼此相似,不同组之间的数据点相对较远。以下是K-means算法的基本工作原理和步骤: 工作原理: 初始化:选择K个初始聚类中心点(质心)。分配:将每个数据点分配到最接近的聚类中心,形成K个簇。更新:根据每个簇中的数据点重新计算聚类中心。迭代:重复步骤2和3,直到满足停止条件(如聚类中心不再改变或达到最大...
基于Python的k-means聚类分析算法的实现与应用,可以用在电商评论、招聘信息等各个领域的文本聚类及指标聚类,效果很好
以微博考研话题为例 思路步骤: 数据清洗: 使用pandas读取数据文件,并进行数据清洗和预处理,包括去除重复值、数据替换等。 数据处理实现: 数据处理的过程如下: 数据清洗主要包括去重和数据转换两个步骤。 首先,通过使用drop_duplicates函数对原始数据进行去重操作。在代码中,根据内容这一列进行去重,并将去重后的结果重新赋值给新的DataFrame。这样可以确保每条内容...
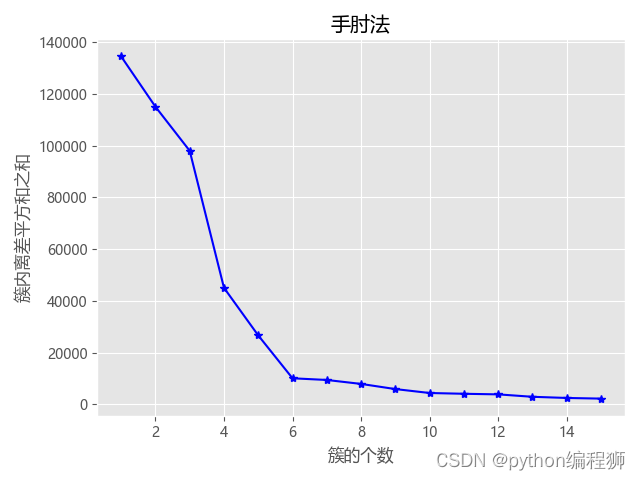
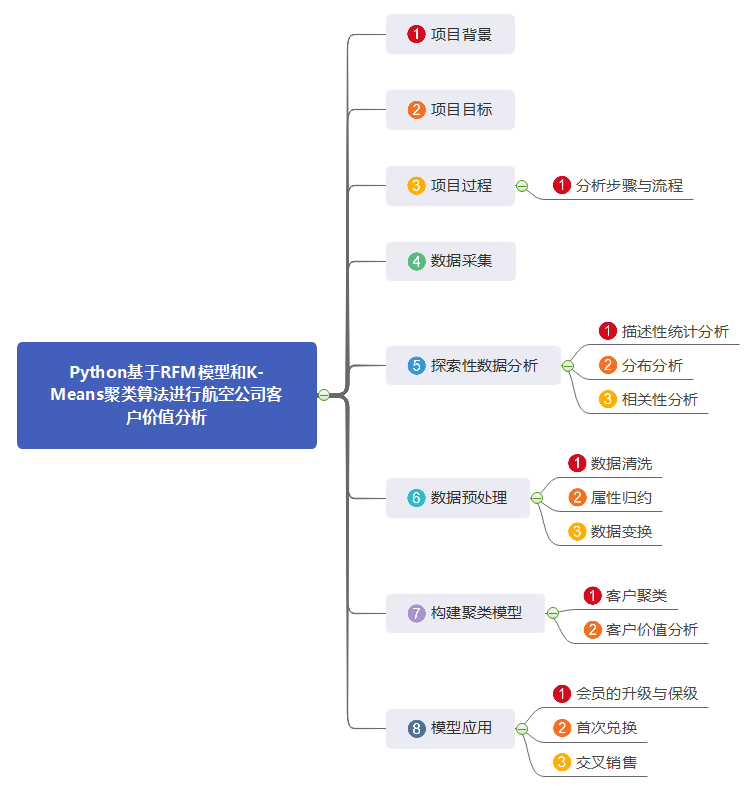
Python基于RFM模型和K-Means聚类算法进行航空公司客户价值分析
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。 ...
【Python 机器学习专栏】K-means 聚类算法在 Python 中的实现
在机器学习领域,聚类分析是一种重要的探索性数据分析方法。K-means 聚类算法是其中一种常用的聚类算法,它简单高效,在许多实际应用中都有广泛的应用。本文将详细介绍 K-means 聚类算法的原理,并展示如何在 Python 中实现该算法。 一、K-means 聚类算法的原理 K-means 聚类算法的基本思想是将数据集划分为 K 个簇&#...
请解释Python中的K-means聚类算法以及如何使用Sklearn库实现它。
K-means聚类是一种无监督学习算法,用于将数据点划分为K个不同的簇(cluster)。每个簇内的数据点彼此相似,而不同簇之间的数据点则具有较大的差异。K-means算法的目标是最小化每个簇内数据点与其质心(centroid)之间的距离之和。 在Python中,可以使用Sklearn库来实现K-m...
Python利用K-Means算法进行图像聚类分割实战(超详细 附源码)
需要源码和图片请点赞关注收藏后评论区留言私信~~~图形分割就是把图像分成若干个特定的、具有独特性质的区域。并提出感兴趣目标的技术和过程,它是由图像处理到图像分析的关键步骤,本案例利用K-Means聚类方法对图像的像素进行聚类实现图像分割打开图像文件并显示 原图像如下 接着显示图像的信息和图像大小显示图像的颜色模式对图像数据进行聚类并显示每个像素的簇标号 最后显示分割后的图像 如下图所示可以看出图....

【Python机器学习】K-Means算法对人脸图像进行聚类实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。算法步骤K-Means容易受初始质心的影响;算法简单,容易实现;算法聚类时,容易产生空簇;算法可能收敛到局部最小值。通过聚类可以实现:发现不同用户群体,从而可以实现精准营销;对文档进行划分;社交网络中,....

【Python机器学习】层次聚类AGNES、二分K-Means算法的讲解及实战演示(图文解释 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~层次聚类在聚类算法中,有一类研究执行过程的算法,它们以其他聚类算法为基础,通过不同的运用方式试图达到提高效率,避免局部最优等目的,这类算法主要有网格聚类和层次聚类算法网格聚类算法强调的是分批统一处理以提高效率,具体的做法是将特征空间划分为若干个网格,网格内的所有样本看成一个单元进行处理,网格聚类算法要与划分聚类或密度聚类算法结合使用,网格聚类算....

【python机器学习】K-Means算法详解及给坐标点聚类实战(附源码和数据集 超详细)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~人们在面对大量未知事物时,往往会采取分而治之的策略,即先将事物按照相似性分成多个组,然后按组对事物进行处理。机器学习里的聚类就是用来完成对事物进行分组的任务一、样本处理聚类算法是对样本集按相似性进行分簇,因此,聚类算法能够运行的前提是要有样本集以及能对样本之间的相似性进行比较的方法。样本的相似性差异也称为样本距离,相似性比较称为距离度量。设样本....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法python相关内容
- python算法应用
- 算法系统python
- 算法python源码
- python算法数据
- 算法python实例
- python算法解析
- 系统python算法
- python c++算法
- 数据python算法
- python人工智能算法
- python网络算法
- python卷积算法
- python tensorflow算法
- 系统python tensorflow算法
- python算法深度学习
- python卷积神经网络算法
- python神经网络算法
- python快速排序算法
- python冒泡排序算法
- 旋转算法python
- 系统python算法模型
- python算法模型
- python tensorflow算法模型
- python算法递归
- 车辆python算法
- python算法训练
- python哈希算法
- 算法python go
- 实战python算法
- python树算法
算法更多python相关
- python算法性能
- python svm算法
- 决策树算法python
- python算法系统
- python算法可视化
- python apriori算法
- python算法聚类
- python lda算法
- 神经网络算法python
- python dbscan算法
- python算法交易
- python算法树
- python knn算法
- 算法数组python
- 天梯算法python
- python算法分类
- python算法数据集
- python决策算法
- python学习算法
- 算法优化python
- 算法链表python
- python k近邻算法
- 算法剑指offer python
- python django网页协同过滤算法
- python算法力扣
- 算法排序python
- python规则算法
- python机器学习k近邻算法
- 树算法python
- 算法字符串python

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注