
如何在使用SparkShell和RDD(新)_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
本文为您介绍如何使用Spark Shell,以及RDD的基础操作。
【Spark】【RDD】初次学习RDD 笔记 汇总 (2)
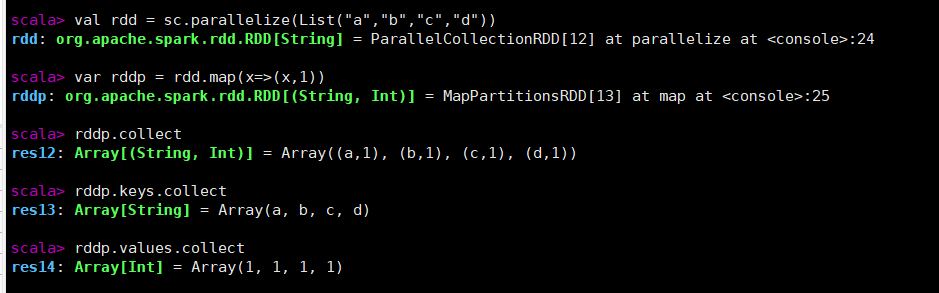
键值对RDDmapValuesval rdd = sc.parallelize(List("a","b","c","d")) //通过map创建键值对 var rddp = rdd.map(x=>(x,1)) rddp.collect rddp.keys.collect rddp.values.collect //通过mapValues让所有Value值加一 rddp.mapValues(....
【Spark】【RDD】初次学习RDD 笔记 汇总 (1)
RDDAuthor:萌狼蓝天【哔哩哔哩】萌狼蓝天【博客】https://mllt.cc【博客园】萌狼蓝天 - 博客园【微信公众号】mllt9920【学习交流QQ群】238948804目录RDD特点创建从内存中创建RDD从外部存储创建RDD1.创建本地文件2.启动spark-shell3.从本地文件系统中读取从HDFS创建RDD1.在HDFS根目录下创建目录(姓名学号)2.上传本地文件到HDFS3....
Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算。 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的C...
Spark RDD概念学习系列之细谈RDD的弹性(十六)
细谈RDD的弹性 所谓,弹性,是指在内存不够时可以与磁盘进行交换。 弹性之一:自动的进行内存和磁盘数据存储的切换 弹性之二:基于Lineage(血缘)的高效容错 弹性之三:Task如果失败会自动进行特定次数的重试 弹性之四:Stage如果失败会自动进行特定次数的...
Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
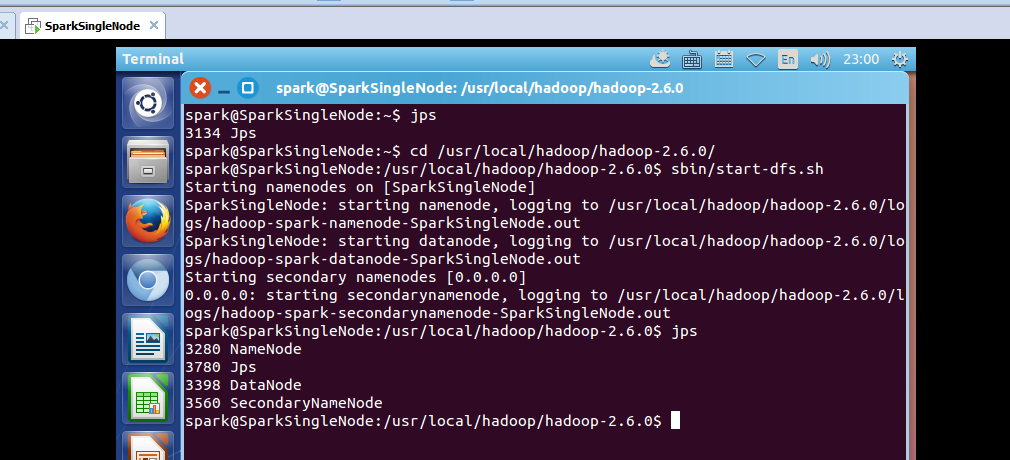
1、rdd持久化 2、广播 3、累加器 1、rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh 启动spark集群 spark@SparkSin...
Spark RDD概念学习系列之RDD的重要内部属性(十五)
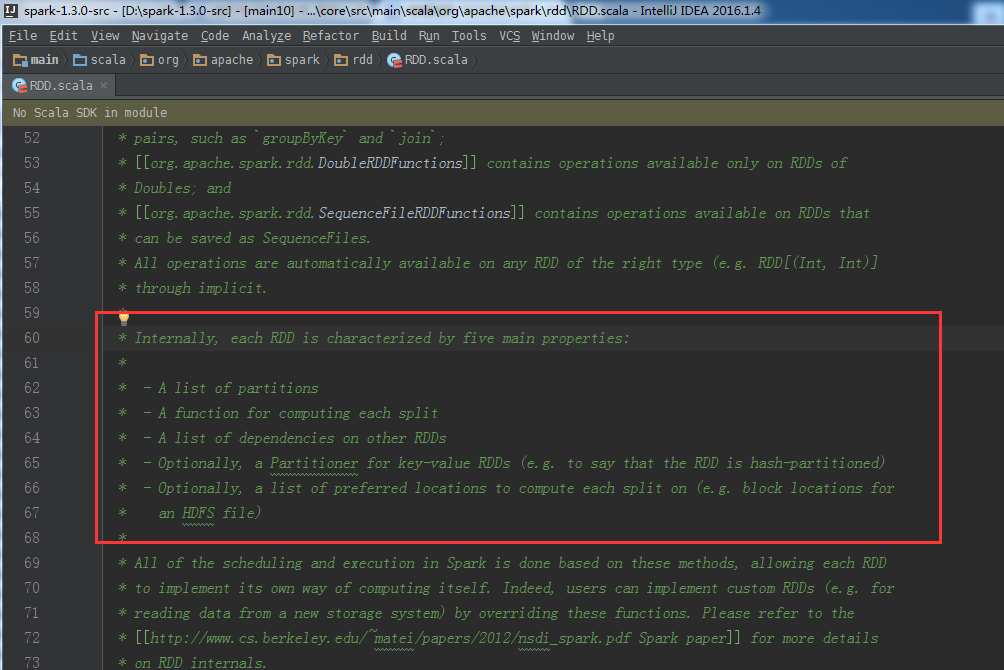
RDD的重要内部属性 通过 RDD 的内部属性,用户可以获取相应的元数据信息。通过这些信息可以支持更复杂的算法或优化。 1)分区列表:通过分区列表可以找到一个 RDD 中包含的所有分区及其所在地址。 2)计算每个分片的函数:通过函数可以对每个数据块进行 RDD 需要进行的用户自定义函数运算。 3)对父 RDD 的依赖列表:为了能够回溯到父 RDD,为容错等提供支持。...
Spark RDD概念学习系列之为什么会引入RDD?(一)
为什么会引入RDD? 我们知道,无论是工业界还是学术界,都已经广泛使用高级集群编程模型来处理日益增长的数据,如MapReduce和Dryad。这些系统将分布式编程简化为自动提供位置感知性调度、容错以及负载均衡,使得大量用户能够在商用集群上分析超大数据集。大多数现有的集群计算系统都是基于非循坏的数据流模型。即从稳定的物理...
Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的。详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类,具体由各子类实现,如MappedRDD、 ShuffledRDD等子类。 Spark将常用的大数据操作都转化成...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkrdd相关内容
- apache spark rdd依赖
- apache spark集群rdd
- apache spark文件rdd
- 大数据apache spark rdd
- apache spark dataframe rdd
- apache spark rdd容错机制
- apache spark rdd编程分区
- apache spark rdd累加
- apache spark集群rdd编程
- apache spark集群rdd编程优化
- apache spark原理rdd
- apache spark rdd优化
- apache spark rdd变量
- apache spark rdd分区
- apache spark RDD持久化
- apache spark RDD编程
- apache spark rdd文件
- apache spark rdd简介
- apache spark rdd rdd-transformation
- apache spark rdd区别
- apache spark rdd flatmap
- apache spark学习rdd依赖持久化
- apache spark编程rdd分区action
- apache spark rdd概述
- apache spark学习rdd
- apache spark学习rdd分区
- apache spark rdd action
- apache spark rdd分区规则
- apache spark rdd算子
- apache spark学习RDD算子
apache spark更多rdd相关
- apache spark rdd分区优化
- apache spark RDD操作
- apache spark精进rdd算子
- apache spark rdd map
- apache spark rdd实战
- apache spark rdd编程案例
- apache spark rdd函数
- apache spark rdd编程action
- apache spark rdd属性
- apache spark rdd dataframe区别
- apache spark rdd方法
- apache spark rdd概念学习
- apache spark rdd作用是什么
- apache spark rdd方法作用是什么
- apache spark rdd容错
- apache spark rdd编程入门
- apache spark rdd func方法作用是什么
- apache spark RDD特性
- apache spark rdd core
- apache spark rdd特点
- apache spark rdd关系
- apache spark初次学习rdd笔记
- apache spark rdd宽依赖
- apache spark rdd弹性
- apache spark rdd groupbykey
- apache spark rdd学习笔记
- apache spark rdd saveastextfile
- apache spark RDD依赖关系
- apache spark rdd scala
- apache spark rdd应用
apache spark您可能感兴趣
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark yarn
- apache spark技术
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注