
使用DeepGPU-LLM镜像构建模型的推理环境
在GPU实例上配置DeepGPU-LLM容器镜像后,可以帮助您快速构建大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)的推理环境,主要应用在智能对话系统、文本分析、编程辅助等自然语言处理业务场景,您无需深入了解底层的硬件优化细节,镜像拉取完成后,无需额外配置即可开箱即用。本文为您介绍如何在GPU实例上使用DeepGPU-LLM容器镜像构建大语言模...
使用TensorRT-LLM构建模型的推理环境
在GPU的实例上安装推理引擎TensorRT-LLM,可以帮助您快速且方便地构建大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)的推理环境,主要应用在智能对话系统、文本分析等自然语言处理业务场景。本文为您介绍如何在GPU实例上安装和使用TensorRT-LLM来快速构建大语言模型的高性能推理优化功能。
DeepGPU-LLM的API接口说明及示例
DeepGPU-LLM作为阿里云开发的一套推理引擎,旨在优化大语言模型在GPU云服务器上的推理过程,为您提供免费的高性能、低延迟推理服务。DeepGPU-LLM提供了一系列的API接口(例如模型加载、模型推理等功能),在GPU云服务器上成功安装DeepGPU-LLM后,您可以调用对应API接口进行模型推理服务,快速提高模型的推理效率和准确性。
安装并使用DeepGPU-LLM进行大语言模型的推理服务
在处理大语言模型(LLM)任务中,您可以根据实际业务部署情况,选择在不同环境(例如GPU云服务器环境或Docker环境)下安装推理引擎DeepGPU-LLM,然后通过使用DeepGPU-LLM实现大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)在GPU上的高性能推理优化功能。
MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理
在人工智能领域,大型语言模型(LLM)的部署和应用正变得日益广泛。然而,随着模型规模的扩大,尤其是在处理长上下文时,计算和内存需求也急剧增加。这一挑战在实际应用中尤为突出,因为长上下文的处理对于许多任务(如文档摘要、问答系统等)至关重要。为了解决这一问题,麻...
基于ModelScope模型库和GPU实例闲置计费功能低成本快速搭建LLM应用
LLM(Large Language Model)是指大型语言模型,是一种采用深度学习技术训练的具有大量参数的自然语言处理模型。您可以基于ModelScope模型库和函数计算GPU实例的闲置计费功能低成本快速搭建LLM应用实现智能问答。
为大型语言模型 (LLM) 提供服务需要多少 GPU 内存?
几乎所有的大型语言模型(LLM)面试中,都会频繁地出现一个问题:“要运行一个大型语言模型,需要多大的GPU内存?”这个问题并非随意提出,它实际上是衡量你对于这些强大模型在实际生产环境中部署和扩展能力理解程度的重要标准。 无论是使用GPT、LLaMA还是其他任何大型语言模型,掌握如何估算所需的GPU内存非常关键。不管你面对的是7B参数的模型还是更大规模的模型,正确地确定硬件规格以支持这些模型都是.....

ModelScope中,对于部署llm,在需要使用多张gpu时,是不是推荐使用偶数张gpu?
ModelScope中,对于部署llm,在需要使用多张gpu时,是不是推荐使用偶数张gpu?
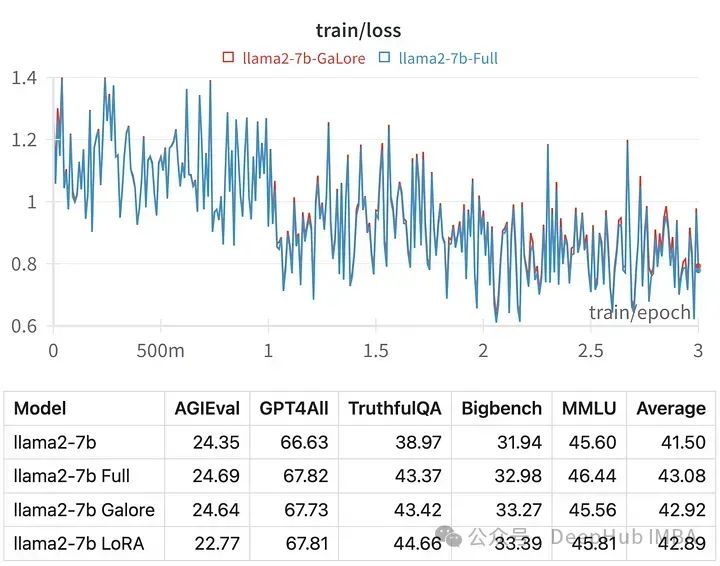
使用GaLore在本地GPU进行高效的LLM调优
训练大型语言模型(llm),即使是那些“只有”70亿个参数的模型,也是一项计算密集型的任务。这种水平的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(LoRA)等参数高效方法,可以在消费级gpu上对大量模型进行微调。 GaLore是一种新的方法,它不是通过直接减少参数的数量,而是通过优化这些参数的训练方式来降低VRAM需求,也就是说GaLore是一种新的模型训.....
LLM大语言模型有个100并发的34b模型的推理需求,不知道需要多大的GPU?
LLM大语言模型有个100并发的34b模型的推理需求,不知道需要多大的GPU?First token需要在2s内,部署的话应该是使用vLLM加速
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。