
构建一个简单的电影信息爬虫项目:使用Scrapy从豆瓣电影网站爬取数据
Scrapy 是一个用 Python 编写的开源框架,它可以帮助你快速地创建和运行爬虫项目,从网页中提取结构化的数据。Scrapy 有以下几个特点: 高性能:Scrapy 使用了异步网络库 Twisted,可以处理大量的并发请求,提高爬取效率。 灵活:Scrapy 提供了丰富的组件和中间件,可以让你定制和扩展爬虫的功能,例如设置代理、更换 User-Agent、处理重定向、过滤重复请求等...

「Python」爬虫-9.Scrapy框架的初识-公交信息爬取
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第23天, 点击查看活动详情Spider实战本文将讲解如何使用scrapy框架完成北京公交信息的获取。目标网址为https://beijing.8684.cn/。在前文的爬虫实战中,已经讲解了如何使用requests和bs4爬取公交站点的信息,感兴趣的话可以先阅读一下「Python」爬虫实战系列-北京公交线路信息爬取(...

Python爬虫:scrapy爬取腾讯社招职位信息
三个文件代码如下:spdier.py# -*- coding: utf-8 -*- # author : pengshiyu # date : 2-18-4-19 import scrapy from scrapy.selector import Selector from tencent_position_item import TencentPositionItem import sys .....
13、web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
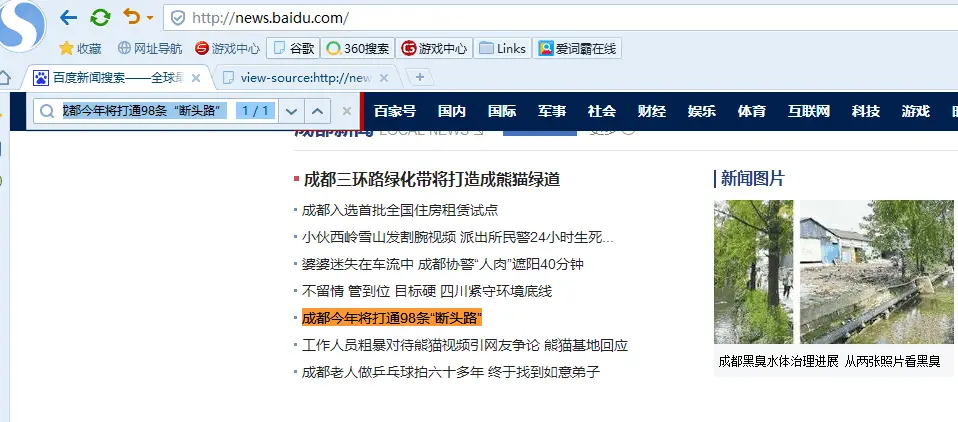
crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多网站,当你浏览器访问时看到的信息,在html源文件里却找不到,由得信息还是滚动条滚动到对应的位置后才显示信息,那么这种一般都是 js 的 Ajax 动态请求生成的信息 我们以百度新闻为列: 1、分析网站 首先我们浏览器打开百度新闻,在网页中间部分找一条新闻信息 然后查看源码,看看在源码里是否有这条新...
爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。 如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython) 1 ...
Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 class UserItem(scrapy.Item): id = Field() name = Field() account_status = Field() all...
Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示: 爬虫分析过程 这里我们找的账号地址是:https://www.z...
Python爬虫之scrapy跨页面爬取信息
昨天凌晨2点醒了看了下向右奔跑的文章,准备来个scrapy跨页面的数据爬取,以简书七日热门数据为例。 1 items.py代码 from scrapy.item import Item,Field class SevendayItem(Item): article_url = Field()#文章链接在首页爬取 author = Field() article = Fi...
教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
来源:http://www.cnblogs.com/wanghzh/p/5824181.html 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力。本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感。 Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
爬虫scrapy相关内容
- scrapy框架爬虫
- scrapy爬虫策略
- 爬虫框架scrapy
- scrapy爬虫应用
- 爬虫scrapy框架
- 爬虫scrapy数据
- scrapy爬虫自定义
- 爬虫开发scrapy
- 爬虫scrapy入门
- scrapy爬虫爬取数据
- scrapy爬虫数据
- scrapy爬虫爬取
- 配置scrapy爬虫
- 爬虫库scrapy
- 爬虫scrapy豆瓣
- 爬虫scrapy xpath
- 爬虫scrapy安装
- 爬虫scrapy框架爬取
- 爬虫scrapy管理工具
- 爬虫scrapy工具
- 爬虫scrapy功能
- 爬虫scrapy代理
- 爬虫scrapy爬虫框架
- 爬虫scrapy框架安装
- scrapy爬虫项目
- scrapy爬虫调试
- scrapy爬虫教程
- scrapy爬虫实例
- scrapy爬虫报错
- scrapy爬虫不报错
爬虫更多scrapy相关
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注