
淘宝反爬虫机制的主要手段有哪些?
淘宝的反爬虫机制主要有以下手段: 一、用户身份识别与验证: User-Agent 识别:通过检测 HTTP 请求头中的 User-Agent 字段来判断请求是否来自合法的浏览器。正常用户使用不同浏览器访问时,User-Agent 会有所不同,而爬虫程序的 User-Agent 可能较为固定或具有某些特定特征。淘宝会根据 Us...

如何设计爬虫代理机制?
目标是抓取几十个网站,但其中只有少数网站的某些域名下会有反爬机制,试着用代理访问,相比不用代理访问速度明显较慢,而且 IP 质量有的很不好,觉得要是本来不用代理的也加代理的话也没必要,但是想让自己的爬虫不被封,还尽可能的有效率,有什么好方法吗,大家都用什么机制?IP 质量难以保证怎么弄啊
如何设计爬虫代理机制?
如何设计爬虫代理机制?目标是抓取几十个网站,但其中只有少数网站的某些域名下会有反爬机制,试着用代理访问,相比不用代理访问速度明显较慢,而且 IP 质量有的很不好,觉得要是本来不用代理的也加代理的话也没必要,但是想让自己的爬虫不被封,还尽可能的有效率,有什么好方法吗,大家都用什么机制?IP 质量难以保证怎么弄啊
突破目标网站的反爬虫机制:Selenium策略分析
在当今信息爆炸的互联网时代,获取数据变得越来越重要,而网络爬虫成为了一种常见的数据获取工具。然而,随着各大网站加强反爬虫技术,爬虫程序面临着越来越多的挑战。本文将以爬取百度搜索结果为例,介绍如何使用Selenium结合一系列策略来突破目标网站的反爬虫机制。 百度搜索反爬虫机制分析百度作为中国最大的搜索引擎之一,拥...
使用Python打造爬虫程序之破茧而出:Python爬虫遭遇反爬虫机制及应对策略
引言 随着网络爬虫技术的广泛应用,越来越多的网站开始实施反爬虫机制,以维护网站的正常运行和数据安全。对于爬虫开发者而言,如何有效应对这些反爬虫机制,确保爬虫的稳定运行,成为了一个亟待解决的问题。本文将介绍常见的反爬虫机制以及相应的应对策略,帮助你在Python爬虫开发中轻松应对挑战。 一、常见的反爬虫机制 Use...
如何检测和应对网站的反爬虫机制?
检测和应对网站的反爬虫机制可以采取以下一些方法: 观察响应状态码:检查 HTTP 请求的响应状态码。常见的反爬虫机制可能会返回特定的状态码,如 403(禁止访问)或 429(请求过多)等。根据状态码可以初步判断是否触发了反爬虫机制。分析响应内容:仔细检查响应的文本内容,看...
如何编写有效的爬虫代码来避免网站的反爬虫机制?
要编写有效的爬虫代码来避免网站的反爬虫机制,可以考虑以下几点: 使用合适的请求频率:限制请求的频率,不要过于频繁地向网站发送请求。可以设置适当的延迟或使用随机延迟来模拟人类的浏览行为。处理请求头:设置合适的请求头信息,例如 User-Agent、Referer 等,使请求看起来更像正常的浏览器访问。...
如何在Puppeteer中设置User-Agent来绕过京东的反爬虫机制?
概述京东作为中国最大的电商平台,为了保护其网站数据的安全性,采取了一系列的反爬虫机制。然而,作为开发者,我们可能需要使用爬虫工具来获取京东的数据。正文Puppeteer 是一个由 Google 开发的 Node.js 库,它提供了高级的 API,用于控制无头浏览器(Headless Browser&...
爬虫遇到反爬机制怎么办? 看看我是如何解决的!
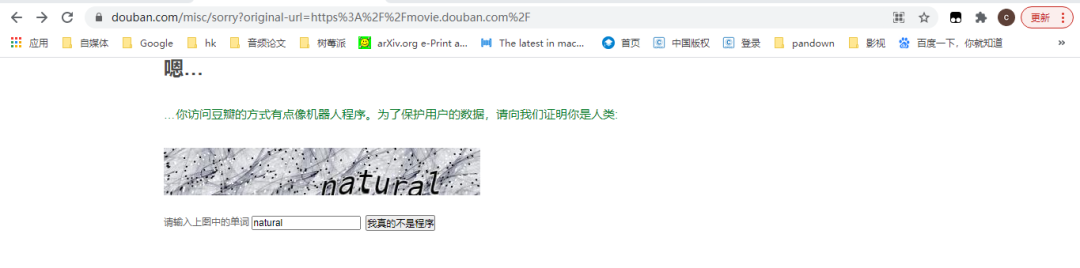
01 前言想着爬取『豆瓣』的用户和电影数据进行『挖掘』,分析用户和电影之间以及各自之间的关系,数据量起码是万级别的。但是在爬取过程中遇到了反爬机制,因此这里给大家分享一下如何解决爬虫的反爬问题?(以豆瓣网站为例)02 问题分析起初代码headers = { 'Host':'movie.douban.com', 'User-Agent':'Mozil...
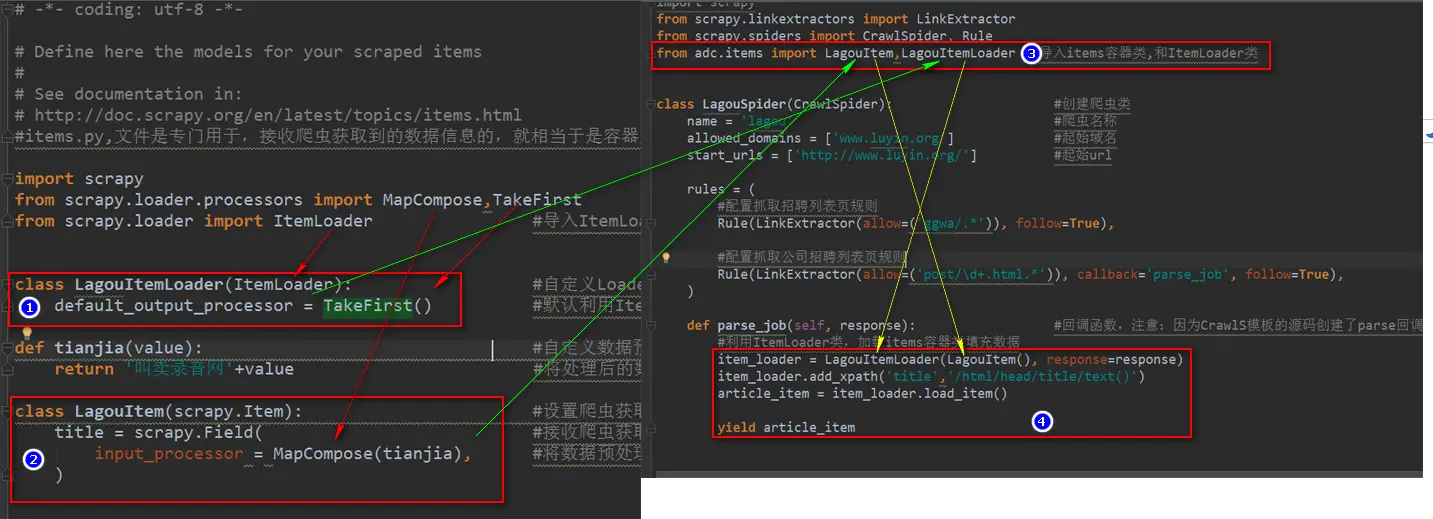
23、 Python快速开发分布式搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
转: http://www.bdyss.cn http://www.swpan.cn 用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates:母版说明 basic 创建基础爬虫文件 crawl ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注