
前端的全栈之路Meteor篇(五):自定义对象序列化的EJSON介绍 - 跨设备的对象传输
在Meteor框架中,EJSON(Extended JSON)是一个扩展了标准JSON的库,旨在支持更多的数据类型。标准JSON仅支持字符串、数字、布尔值、数组和对象等基本数据类型,而EJSON允许开发者在Meteor应用中传输更复杂的数据类型,例如Date、Binary数据,甚至是自定义对象。 E...
大数据-61 Kafka 高级特性 消息消费02-主题与分区 自定义反序列化 拦截器 位移提交 位移管理 重平衡
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(正在更新…) ...

大数据-58 Kafka 高级特性 消息发送02-自定义序列化器、自定义分区器 Java代码实现
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...

实现自定义序列化和反序列化控制的5种方式
一、自定义 Serializer 和 Deserializer 你可以编写自定义的序列化器(Serializer)和反序列化器(Deserializer),并将它们应用到特定的类或属性上。通过实现 JsonSerializer 和 JsonDeserializer 接口,你可以完全控制序列化和反序列化过程中的行为,包括如何读取属性、生成 JSON 或者解析 JSON 等。 当你需...
MapReduce编程模型——自定义序列化类实现多指标统计
Hadoop序列化 序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。 为什么要序列化 一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。然而...

Kafka【付诸实践 01】生产者发送消息的过程描述及设计+创建生产者并发送消息(同步、异步)+自定义分区器+自定义序列化器+生产者其他属性说明(实例源码粘贴可用)【一篇学会使用Kafka生产者】
1.生产者发送消息的过程及生产者设计 1.1 消息发送过程 生产者发送消息的过程描述: Kafka 会将发送消息包装为 ProducerRecord 对象, ProducerRecord 对象包含了目标主题和要发送的内容,同时还可以指定键和分区。为了使其能够在网络上传输,在发送 ProducerRecord 对象前生产者会把键和值对象序列化成字节数组。 接下来,数据被传给分...

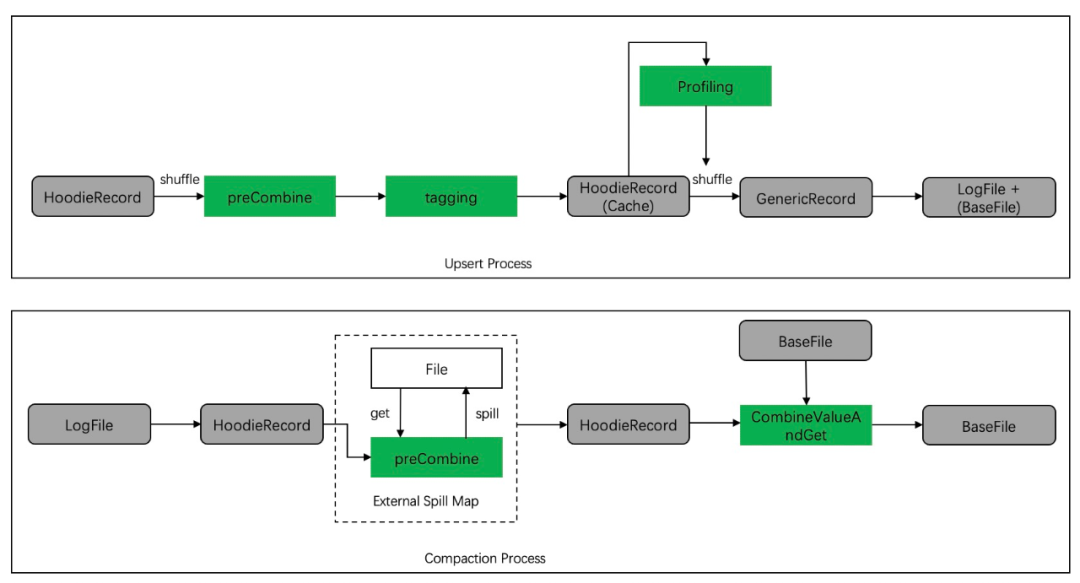
硬核!Apache Hudi中自定义序列化和数据写入逻辑
1. 介绍 在Apache Hudi中,Hudi的一条数据使用HoodieRecord这个类表示,其中包含了hoodie的主键,record的分区文件位置,还有今天本文的关键,payload。payload是一个条数据的内容的抽象,决定了同一个主键的数据的增删改查逻辑也决定了其序列化的方式。通过对payload的自定义,可以实现数据的灵活合并,数据的自定义编码序列化等,丰富Hudi现有的...
LocalDateTime的全局自定义序列化
一、 引用依赖 <dependency> <groupId>com.fasterxml.jackson.datatype</groupId> <artifactId>jackson-datatype-jsr310&...
open-feign自定义反序列化decoder
主要是解决map类型擦除的问题,GlobalResponse继承了Map 代码如下: import cn.hutool.core.util.TypeUtil; import com.fasterxml.jackson.core.type.TypeReference; impor...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。