
创建Hive Catalog
配置Hive Catalog后,您可以在Flink开发控制台直接读取Hive元数据,无需再手动注册Hive表,提高作业开发的效率且保证数据的正确性。本文为您介绍如何配置Hive元数据、创建和使用Hive Catalog等。
注册Hive Kerberos集群
在实时计算控制台上注册Hive Kerberos集群信息后,可以访问支持Kerberos的Hive。本文为您介绍如何注册Hive Kerberos集群。
Flink Hive SQL作业快速入门
实时计算Flink版支持使用Hive方言创建批处理作业,通过兼容Hive SQL语法增强与Hive互操作性,便于从现有Hive作业平滑迁移至实时计算管理控制台。
Flink CDC + Hudi + Hive + Presto构建实时数据湖最佳实践
1. 测试过程环境版本说明 Flink1.13.1 Scala2.11 CDH6.2.0 Hadoop3.0.0 Hive2.1.1 Hudi0.10(master) PrestoDB0.256 Mysql5.7 2. 集群服务器基础环境 2.1 Maven和JDK环境版本 ...
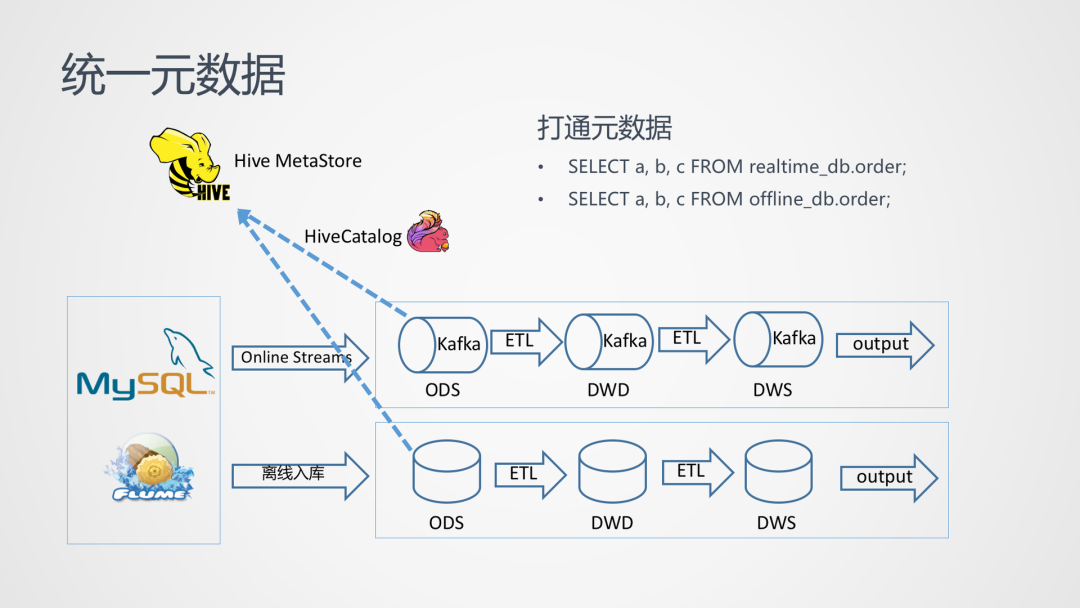
基于 Flink + Hive 构建流批一体准实时数仓
基于 Hive 的离线数仓往往是企业大数据生产系统中不可缺少的一环。Hive 数仓有很高的成熟度和稳定性,但由于它是离线的,延时很大。在一些对延时要求比较高的场景,需要另外搭建基于 Flink 的实时数仓,将链路延时降低到秒级。但是一套离线数仓加一套实时数仓的架构会带来超过两倍的资源消耗,甚至导致重复开发。 想要搭建流式链路就必须得抛弃现有的 Hive 数仓吗?并不是,借助 Flink 可以实.....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
实时计算 Flink版hive相关内容
- 实时计算 Flink版mysql hive
- hive实时计算 Flink版
- hive sql实时计算 Flink版
- 实时计算 Flink版postgresql hive断点续传
- 实时计算 Flink版sql hive
- 实时计算 Flink版hive函数
- 实时计算 Flink版flinksql hive
- 实时计算 Flink版hive元数据
- 实时计算 Flink版hudi hive
- 实时计算 Flink版kerberos认证hive
- 实时计算 Flink版连接hive
- 实时计算 Flink版hive分区
- 实时计算 Flink版查询hive
- 实时计算 Flink版hive hdfs文件
- 实时计算 Flink版hive hdfs
- 实时计算 Flink版hive文件
- 实时计算 Flink版hudi hive spark
- 实时计算 Flink版hive spark
- 实时计算 Flink版hive分区表
- 实时计算 Flink版hive办法
- 实时计算 Flink版hive explode
- 实时计算 Flink版hive报错
- 实时计算 Flink版hive token
- 实时计算 Flink版场景hive
- 实时计算 Flink版hive格式
- 实时计算 Flink版hive映射
- 实时计算 Flink版hdfs hive
- 实时计算 Flink版文件hive
- 实时计算 Flink版hive包
- 实时计算 Flink版hive sql
实时计算 Flink版更多hive相关
- 实时计算 Flink版hive udf
- 实时计算 Flink版hive udf函数
- 实时计算 Flink版hive解决方法
- 实时计算 Flink版hive查询
- 实时计算 Flink版hive source
- 实时计算 Flink版hive hbase
- 实时计算 Flink版cli hive
- 实时计算 Flink版实时同步hive
- 实时计算 Flink版数据源hive
- 实时计算 Flink版iceberg hive
- 实时计算 Flink版 hive
- 实时计算 Flink版hive异常
- 实时计算 Flink版读写hive
- 实时计算 Flink版hive集成
- 实时计算 Flink版sql-client hive
- 实时计算 Flink版hive数仓
- 实时计算 Flink版hive功能
- hive catalog实时计算 Flink版
- 实时计算 Flink版hive orc
- 实时计算 Flink版join hive
- 实时计算 Flink版hive数据源
- 实时计算 Flink版table hive
- 实时计算 Flink版使用hive
- 实时计算 Flink版streaming hive
- hive小文件实时计算 Flink版
- 实时计算 Flink版读取hive
- flink1.10 hive实时计算 Flink版
- 实时计算 Flink版hive catalog
- 实时计算 Flink版hive方案
- 实时计算 Flink版hive demo
实时计算 Flink版您可能感兴趣
- 实时计算 Flink版b站
- 实时计算 Flink版云原生
- 实时计算 Flink版实践
- 实时计算 Flink版CDC
- 实时计算 Flink版kafka
- 实时计算 Flink版数据链路
- 实时计算 Flink版湖仓
- 实时计算 Flink版湖仓一体
- 实时计算 Flink版Hologres
- 实时计算 Flink版batch
- 实时计算 Flink版数据
- 实时计算 Flink版SQL
- 实时计算 Flink版mysql
- 实时计算 Flink版报错
- 实时计算 Flink版同步
- 实时计算 Flink版任务
- 实时计算 Flink版flink
- 实时计算 Flink版实时计算
- 实时计算 Flink版版本
- 实时计算 Flink版oracle
- 实时计算 Flink版表
- 实时计算 Flink版配置
- 实时计算 Flink版产品
- 实时计算 Flink版Apache
- 实时计算 Flink版设置
- 实时计算 Flink版作业
- 实时计算 Flink版模式
- 实时计算 Flink版数据库
- 实时计算 Flink版运行
- 实时计算 Flink版连接

