
【Python强化学习】时序差分法Sarsa算法和Qlearning算法在冰湖问题中实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~时序差分算法时序差分法在一步采样之后就更新动作值函数Q(s,a),而不是等轨迹的采样全部完成后再更新动作值函数。在时序差分法中,对轨迹中的当前步的(s,a)的累积折扣回报G,用立即回报和下一步的(s^′,a^′)的折扣动作值函数之和r+γQ(s^′,a^′)来计算,即:G=r+γQ(s^′,a^′)在递增计算动作值函数时,用一个[0,1]之间的步长α来....
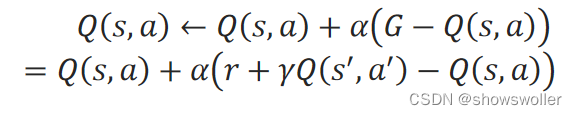
【PyTorch深度强化学习】TD3算法(双延迟-确定策略梯度算法)的讲解及实战(超详细 附源码)
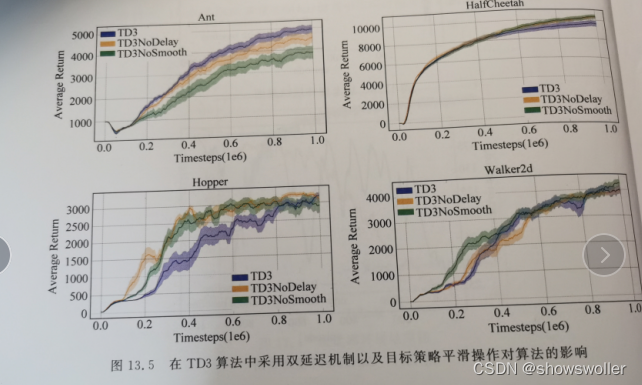
需要源码请点赞关注收藏后评论区留言~~~一、双延迟-确定策略梯度算法在DDPG算法基础上,TD3算法的主要目的在于解决AC框架中,由函数逼近引入的偏差和方差问题。一方面,由于方差会引起过高估计,为解决过高估计问题,TD3将截断式双Q学习(clipped Double Q-Learning)应用于AC框架;另一方面,高方差会引起误差累积,为解决误差累积问题,TD3分别采用延迟策略更新和添加噪声平滑....
【PyTorch深度强化学习】DDPG算法的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~一、DDPG背景及简介 在动作离散的强化学习任务中,通常可以遍历所有的动作来计算动作值函数q(s,a)q(s,a),从而得到最优动作值函数q∗(s,a)q∗(s,a) 。但在大规模连续动作空间中,遍历所有动作是不现实,且计算代价过大。针对解决连续动作空间问题,2016年TP Lillicrap等人提出深度确定性策略梯度算法(Deep Determ....

深度强化学习中Double DQN算法(Q-Learning+CNN)的讲解及在Asterix游戏上的实战(超详细 附源码)
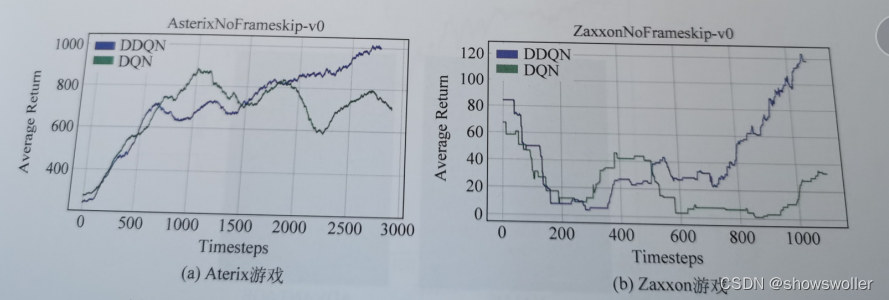
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、核心思想针对DQN中出现的高估问题,有人提出深度双Q网络算法(DDQN),该算法是将强化学习中的双Q学习应用于DQN中。在强化学习中,双Q学习的提出能在一定程度上缓解Q学习带来的过高估计问题。DDQN的主要思想是在目标值计算时将动作的选择和评估分离,在更新过程中,利用两个网络来学习两组权重,分别是预测网络的权重W和目标网络的权重W',在D....
深度强化学习中利用N-步TD预测算法在随机漫步应用中实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留下QQ或者私信~~~一、N-步TD预测N步TD预测算法在TD(0)和MC之间架起了一座桥梁,而TD(L)算法则能进一步实现两者之间的无缝衔接。下面介绍N步TD预测N步TD算法更新方式介于TD(0)和MC之间,该类算法利用未来多步奖赏和多部之后的值函数估计求得目标值,例如两步更新就是利用未来两步奖赏和两步之后的值函数估计得到两步回报。N步TD属于TD(时序差分法)当....

深度强化学习中利用Q-Learngin和期望Sarsa算法确定机器人最优策略实战(超详细 附源码)
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、Q-Learning算法Q-Learning算法中动作值函数Q的更新方向是最优动作值函数q,而与Agent所遵循的行为策略无关,在评估动作值函数Q时,更新目标为最优动作值函数q的直接近似,故需要遍历当前状态的所有动作,在所有状态都能被无限次访问的前提下,Q-Learning算法能以1的概率收敛到最优动作值函数和最优策略下图是估算最优策略的....

深度强化学习之gym扫地机器人环境的搭建(持续更新算法,附源码,python实现)
想要源码可以点赞关注收藏后评论区留下QQ邮箱本次利用gym搭建一个扫地机器人环境,描述如下:在一个5×5的扫地机器人环境中,有一个垃圾和一个充电桩,到达[5,4]即图标19处机器人捡到垃圾,并结束游戏。同时获得+3的奖赏。左下角[1,1]处有一个充电桩,机器人到达充电桩可以充电且不再行走,获得+1的奖赏。环境中间[3,3]处有一个障碍物,机器人无法通过。扫地机器人具体流程如下1:每局游戏开始 机....
深度强化学习之gym扫地机器人环境的搭建(持续更新算法,附源码,python实现)
想要源码可以点赞关注收藏后评论区留下QQ邮箱本次利用gym搭建一个扫地机器人环境,描述如下:在一个5×5的扫地机器人环境中,有一个垃圾和一个充电桩,到达[5,4]即图标19处机器人捡到垃圾,并结束游戏。同时获得+3的奖赏。左下角[1,1]处有一个充电桩,机器人到达充电桩可以充电且不再行走,获得+1的奖赏。环境中间[3,3]处有一个障碍物,机器人无法通过。扫地机器人具体流程如下1:每局游戏开始 机....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多源码相关

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注