
【优秀python web毕设案例】基于协同过滤算法的酒店推荐系统,django框架+bootstrap前端+echarts可视化,有后台有爬虫
随着旅游业的蓬勃发展,消费者对住宿环境的需求日益多样化和个性化。酒店和民宿作为旅行中不可或缺的一部分,其选择不仅影响旅行的舒适度,更直接影响到整体旅游体验。传统的住宿推荐系统往往依赖于用户的历史行为和简单的评分反馈,难以精准捕捉用户的实际需求。因此,构建一个基于 Django 的酒店民宿可视化推荐系统显得尤为重要。 Django 作为一个高效的 Python Web 框架,能够快速构建和部署复.....

基于朴素贝叶斯算法的新闻类型预测,django框架开发,前端bootstrap,有爬虫有数据库
背景 在当今信息爆炸的时代,新闻内容的分类和预测对于用户个性化推荐和信息检索至关重要。基于朴素贝叶斯算法的新闻类型预测系统结合了机器学习和自然语言处理技术,能够根据新闻内容自动进行分类,提高新闻处理效率和准确性。采用Django框架进行开发,可以构建用户友好的Web应用界面,方便用户进行新闻类型预测查询和结果展示。通过爬虫技术实现新闻数据的实时获取和更新,将爬取的新闻数据存储在数据库中,为模型.....
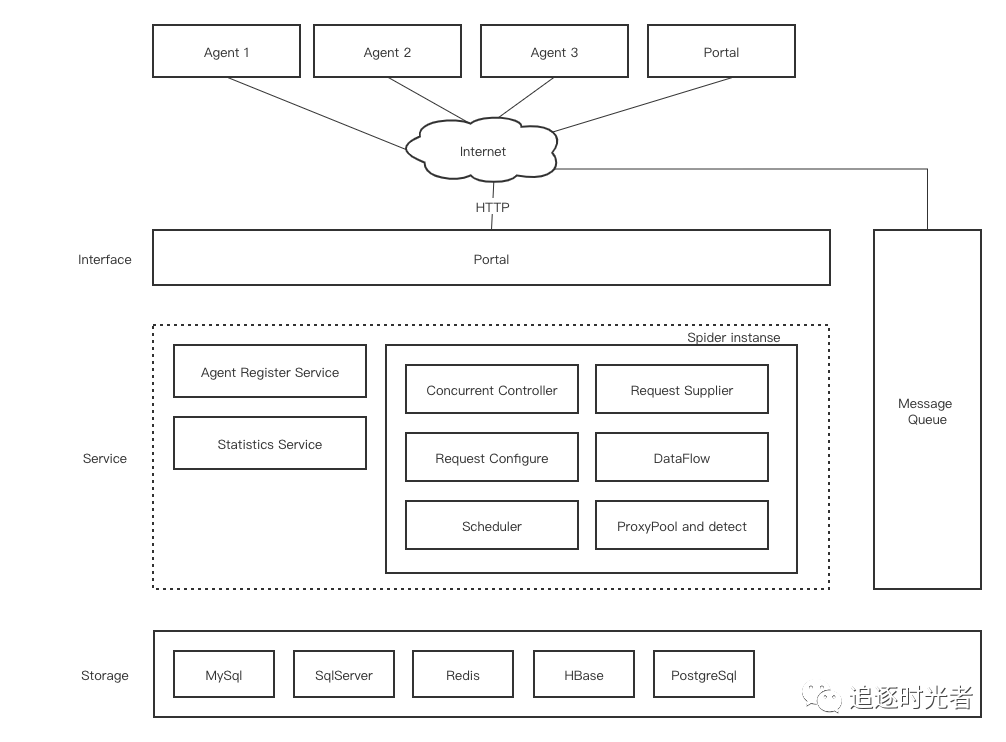
.NET使用分布式网络爬虫框架DotnetSpider快速开发爬虫功能
前言前段时间有同学在微信群里提问,要使用.NET开发一个简单的爬虫功能但是没有做过无从下手。今天给大家推荐一个轻量、灵活、高性能、跨平台的分布式网络爬虫框架(可以帮助 .NET 工程师快速的完成爬虫的开发):DotnetSpider。注意:为了自身安全请在国家法律允许范围内开发网络爬虫功能。框架设计图整个爬虫设计是纯异步的,利用消息队列进行各个组件的解耦,若是只需要单机爬虫则不需要做任何额外的配....
Crawler之Scrapy:Python实现scrapy框架爬虫两个网址下载网页内容信息
输出结果后期更新……实现代码import scrapyclass DmozSpider(scrapy.Spider): name ="dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "https://dm...
scrapy框架通用爬虫、深度爬虫、分布式爬虫、分布式深度爬虫,源码解析及应用
scrapy框架是爬虫界最为强大的框架,没有之一,它的强大在于它的高可扩展性和低耦合,使使用者能够轻松的实现更改和补充。 其中内置三种爬虫主程序模板,scrapy.Spider、RedisSpider、CrawlSpider、RedisCrawlSpider(深度分布式爬虫)分别为别为一般爬虫、分布式爬虫、深度爬虫提供内部逻辑;下面将从源码和应用来学习, scrapy.Spider 源码: ""....
Scrapy框架--通用爬虫Broad Crawls(下,具体代码实现)
通过前面两章的熟悉,这里开始实现具体的爬虫代码 广西人才网 以广西人才网为例,演示基础爬虫代码实现,逻辑: 配置Rule规则:设置allow的正则-->设置回调函数 通过回调函数获取想要的信息 具体的代码实现: import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders impor...
Scrapy笔框架--通用爬虫Broad Crawls(中)
rules = ( Rule(LinkExtractor(allow=r'WebPage/Company.*'),follow=True,callback='parse_company'), Rule(LinkExtractor(allow=r'WebPage/JobDetail.*'), callback='parse_item', follow=True), ...
Scrapy框架--通用爬虫Broad Crawls(上)
通用爬虫(Broad Crawls)介绍 [传送:中文文档介绍],里面除了介绍还有很多配置选项。 通用爬虫一般有以下通用特性: 其爬取大量(一般来说是无限)的网站而不是特定的一些网站。 其不会将整个网站都爬取完毕,因为这十分不实际(或者说是不可能)完成的。相反,其会限制爬取的时间及数量。 其在逻辑上十分简单(相较于具有很多提取规则的复杂的spider),数据会在另外的阶段进行后处理(pos...
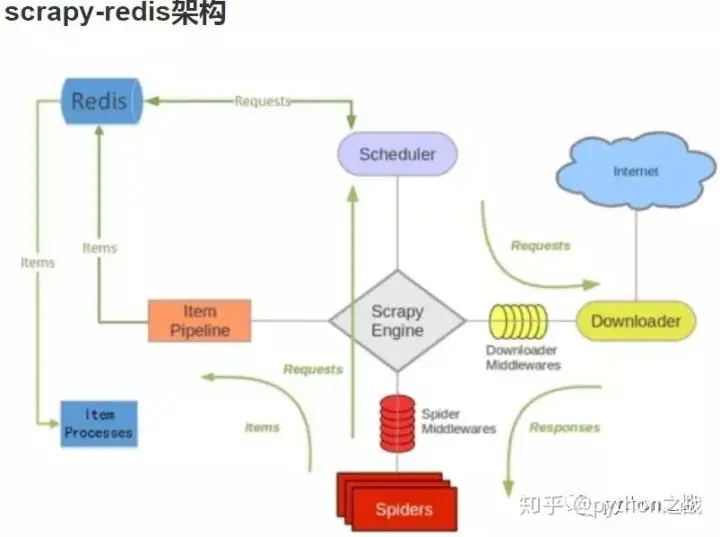
Scrapy框架-分布式爬虫实现及scrapy_redis使用
scrapy是不支持分布式的。分布式爬虫应该是在多台服务器(A B C服务器),他们不会重复交叉爬取(需要用到状态管理器)。 有主从之分的分布式结构图 重点 一、我的机器是Linux系统或者是MacOSX系统,不是Windows 二、区别,事实上,分布式爬虫有几个不同的需求,会导致结构不一样,我举个例子: 1、我需要多台机器同时爬取目标url并且同时从url中抽取数据,N台机器做一模...
Scrapy框架-通过Scrapyd来部署爬虫
前言 爬虫写完了,很多时候本机部署就可以了,但是总有需要部署到服务器的需求,网上的文章也比较多,复制的也比较多,从下午3点钟摸索到晚上22点,这里记录一下。 环境情况 我的系统是Deepin 开发环境也是Deepin,python 环境用的是Anaconda建立的虚拟环境(python3.6) 部署系统是本机的Deepin 部署环境由于在本机部署,所以跟开发环境一致(就是这里有个坑) 用到的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注