
如何访问OSS-HDFS数据
Hologres从V1.3.26版本开始,支持读写存储于OSS-HDFS上的数据。本文为您介绍基于DLF访问OSS-HDFS数据湖数据的使用方法。
通过数据湖构建DLF构建一站式数据入湖与分析
企业构建和应用数据湖一般需要经历数据入湖、数据湖存储与管理、数据湖探索与分析等几个过程。本文主要介绍基于阿里云数据湖构建(DLF)构建一站式的数据入湖与分析实战。
Yotpo构建零延迟数据湖实践
1. 介绍 随着系统变得越来越复杂,我们需要更多的解决方案来集中维护大量数据,以便对其进行监控和查询,而又不会干扰运营数据库。在Yotpo,我们有许多微服务和数据库,因此将数据传输到集中式数据湖中的需求至关重要。我们一直在寻找易于使用的基础架构(仅需配置),以节省工程师的时间。 变更数据捕获(Changed Data Capture,简称为CDC)架构是指跟踪变更的数据,以便可以...
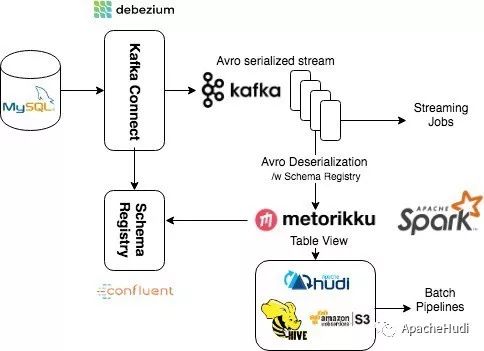
Apache Hudi在Linkflow构建实时数据湖的生产实践
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又会作为MA (Marketing Automation) 系统的数据源,从而实现对特定人群...
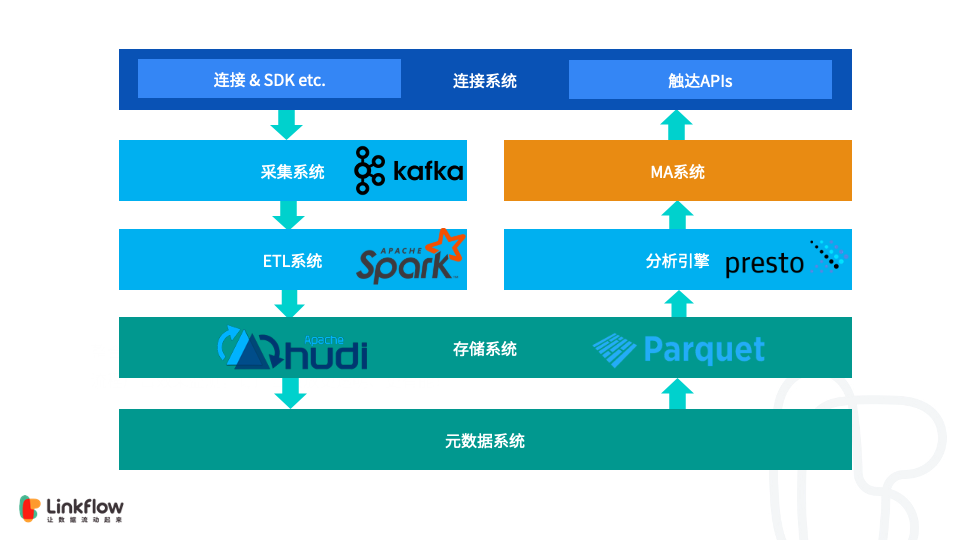
字节跳动基于Apache Hudi构建EB级数据湖实践
接下来将分为场景需求、设计选型、功能支持、性能调优、未来展望五部分介绍Hudi在字节跳动推荐系统中的实践。 ...


B 站构建实时数据湖的探索和实践
摘要:本文整理自 bilibili 大数据实时团队资深开发工程师周晖栋,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分:背景和痛点场景探索基建优化总结和展望点击查看原文视频 & 演讲PPT一、背景和痛点在大数据场景应用中,业务不仅要计算数据结果,而且要保障时效性。目前,我司演化出两条链路。时效性高的数据走 Kafka、Flink 实时链路....

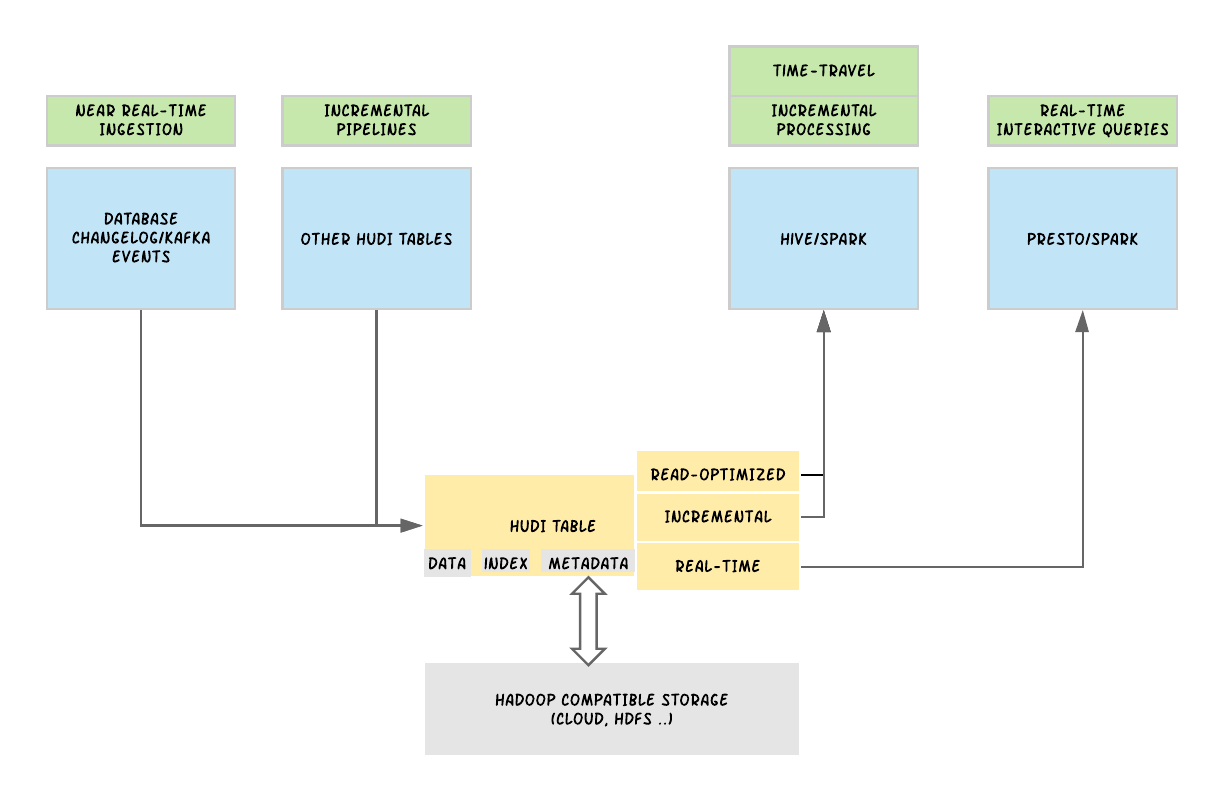
Uber基于Apache Hudi构建PB级数据湖实践
1. 引言从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全、无缝的运输和交付体验需要可靠、高性能的大规模数据存储和分析。2016年,Uber开发了增量处理框架Apache Hudi,以低延迟和高效率为关键业务数据管道赋能。一年后,我们开源了该解决方案,以使得其他有需要的组织也可以利用Hudi的优势。接着在2019年,我们履行承诺,进一步将其捐赠给了Apache Software....
Apache Hudi 在 B 站构建实时数据湖的实践
本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:传统离线数仓痛点数据湖技术方案Hudi 任务稳定性保障数据入湖实践增量数据湖平台收益社区贡献未来的发展与思考GitHub 地址 https://github.com/apache/flink欢迎大家给 Flink 点赞送 star~一、传统离线数仓痛点1. 痛点之前 B 站数仓....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
