
Scrapy框架 -- 深度爬取并持久化保存图片
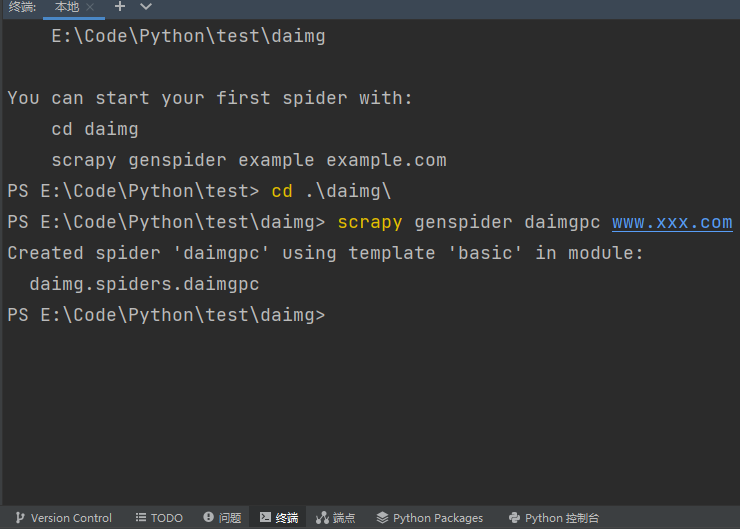
一、新建一个Scrapy项目daimgscrapy startproject daimg二、进入该项目并创建爬虫文件daimgpccd daimg scrapy genspider daimgpc www.xxx.com三、修改配置文件settings.pyROBOTSTXT_OBEY = False LOG_LEVEL = 'ERROR' USER_AGENT = "Mozilla/5.0 .....
scrapy爬取百度图片时,出现jsondecodeerror?报错
我按照网上的教程,在scrapy shell中进行调试。 scrapy shell http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=皇马&cl=2&lm=-1&ie=utf-8&...
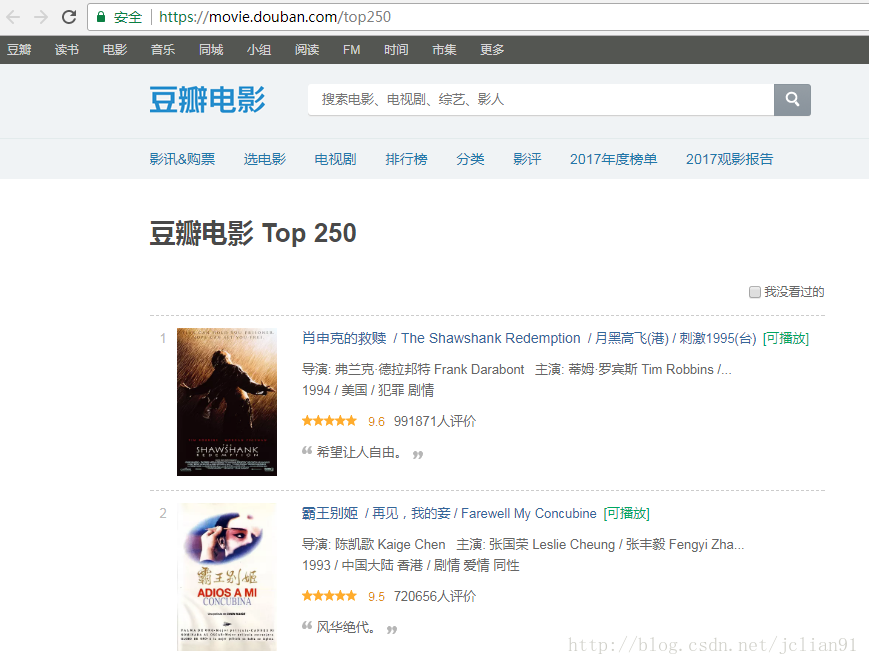
Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架——Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影Top250, 主要解决的问题有: 如何利用ImagesPipeline来下载图片 如何对下载后的图片重命名,这是因为Scrapy默认用Hash值来保存文件,这并不是我们想要的 首先我们要爬...
使用scrapy ImagesPipeline爬取图片资源
版权声明:本文可能为博主原创文章,若标明出处可随便转载。 https://blog.csdn.net/Jailman/article/details/79170849 这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里。 scrapy star...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Scrapy您可能感兴趣
大数据
大数据计算实践乐园,近距离学习前沿技术
+关注