
Dataflow集群如何连接DLF,并读取Hudi全量数据
DataFlow集群可以通过数据湖构建(DLF)的统一元数据服务,访问DataLake集群或自定义集群中的Hudi表数据。本文为您介绍DataFlow集群如何连接DLF并读取Hudi全量数据。
Hudi Catalog
Hudi Catalog是一种External Catalog。通过Hudi Catalog,您不需要执行数据导入就可以直接查询Apache Hudi里的数据。此外,您还可以基于Hudi Catalog ,结合INSERT INTO能力来实现数据转换和导入。StarRocks从2.4版本开始支持Hudi Catalog。
Hudi数据源
Apache Hudi是一种数据湖存储格式,在Hadoop文件系统之上提供了更新数据、删除数据以及消费变化数据的能力,详情请参见Apache Hudi。本文为您介绍如何在EMR Serverless Spark中实现Hudi表的读取与写入操作。
在EMR StarRocks上查询Hudi数据
Hudi Catalog是一种External Catalog。通过Hudi Catalog,您可以直接查询Hudi中的数据。本文为您介绍如何在E-MapReduce的StarRocks集群上创建和查看Hudi Catalog。
使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模、可靠性、成本效率等方面。最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分析数据。尽管这些工具功能强大,但是在处理需要进行增量数据处理以及记录级别插入,更新和删除场景时,仍然非常具有挑战。 与客户交谈时,我们发现有些场景需要处理对单条记录的增量更新,例如: ...
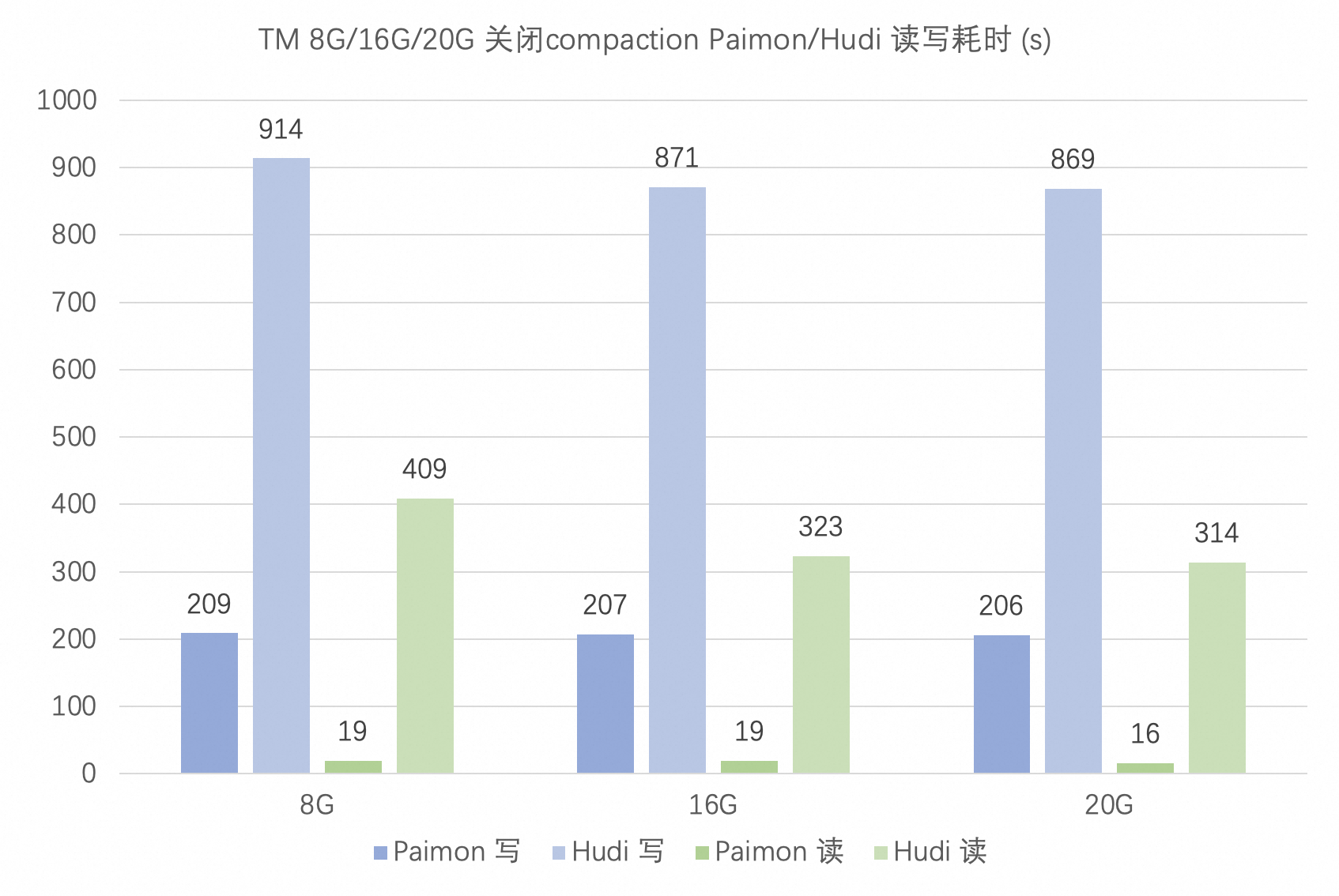
阿里云 EMR 基于 Paimon 和 Hudi 构建 Streaming Lakehouse
1. 背景信息数据湖与传统的数据仓库相比,可以更灵活地处理各种类型的数据,并支持高度可扩展的存储,通常被用于大数据分析。为了支持准实时乃至实时的数据处理,数据湖需要能够快速地接收和存储数据(数据入湖),同时提供低延迟的查询性能以满足分析需求。Apache Paimon 和 Apache Hudi 作为数据湖存储格式,有着高吞吐的写入和低延迟的查询性能,是构建数据湖的常用组件。本文将在阿里云EMR....
请问下阿里云E-MapReduce emr的 trino读取hudi可以设置时区么?
请问下阿里云E-MapReduce emr的 trino读取hudi可以设置时区么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。