
Apache Hudi Savepoint实现分析
1. 介绍 Hudi提供了savepoint机制,即可对instant进行备份,当后续出现提交错误时,便可rollback至指定savepoint,这对于线上系统至为重要,而savepoint由hudi-CLI手动触发,下面分析savepoint的实现机制。 2. 分析 2.1 创建savepoint 创建savepoint的入口为 HoodieWriteClie...
Apache Hudi:统一批和近实时分析的存储和服务
一篇由三位Hudi PMC在2018年做的关于Hudi的分享,介绍了Hudi产生的背景及设计,现在看来也很有意义。 分为产生背景、动机、设计、使用案例、demo几个模块讲解。 ...

Apache Hudi Rollback实现分析
1. 介绍 在发现有些commit出错时,可使用Hudi提供的rollback回滚至指定的commit,这样可防止出现错误的结果,并且当一次commit失败时,也会进行rollback操作,保证一次commit的原子性。 2. 分析 rollback(回滚)的入口在 HoodieWriteClient#rollback,其依赖 HoodieWriteClient#roll...
Apache Hudi索引实现分析(一)之HoodieBloomIndex
1. 介绍 为了加快数据的upsert,Hudi提供了索引机制,现在Hudi内置支持四种索引:HoodieBloomIndex、HoodieGlobalBloomIndex、InMemoryHashIndex和HBaseIndex,下面对Hudi基于BloomFilter索引机制进行分析。 2. 分析 对于所有索引类型的基类HoodieIndex,其包含了如下核心的抽象方...
Apache Hudi索引实现分析(二)之HoodieGlobalBloomIndex
1. 介绍 前面分析了Hudi默认的索引实现HoodieBloomIndex,其是基于分区记录所在文件,即分区路径+recordKey唯一即可,Hudi还提供了HoodieGlobalBloomIndex的实现,即全局索引实现,只需要recordKey唯一即可,下面分析其实现。 2. 分析 HoodieGlobalBloomIndex是HoodieBloomIndex的子...
Apache Hudi索引实现分析(三)之HBaseIndex
1. 介绍 前面分析了基于过滤器的索引,接着分析基于外部存储系统的索引实现:HBaseIndex。对于想自定义实现Index具有一定的借鉴作用。 2. 分析 HBaseIndex也是HoodieIndex的子类实现,其实现了父类的两个核心方法。 // 给输入记录...
基于 Apache Hudi 构建分析型数据湖
为了更好地发展业务,每个组织都在迅速采用分析。在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能。通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特定受众。只有当我们能够大规模提供分析时,这一切才有可能。 对数据湖的需求 在 NoBrokercom[1],出于操作目的,事务数据存储在基于 SQL 的数据库中,事件数据存储在 No-S...
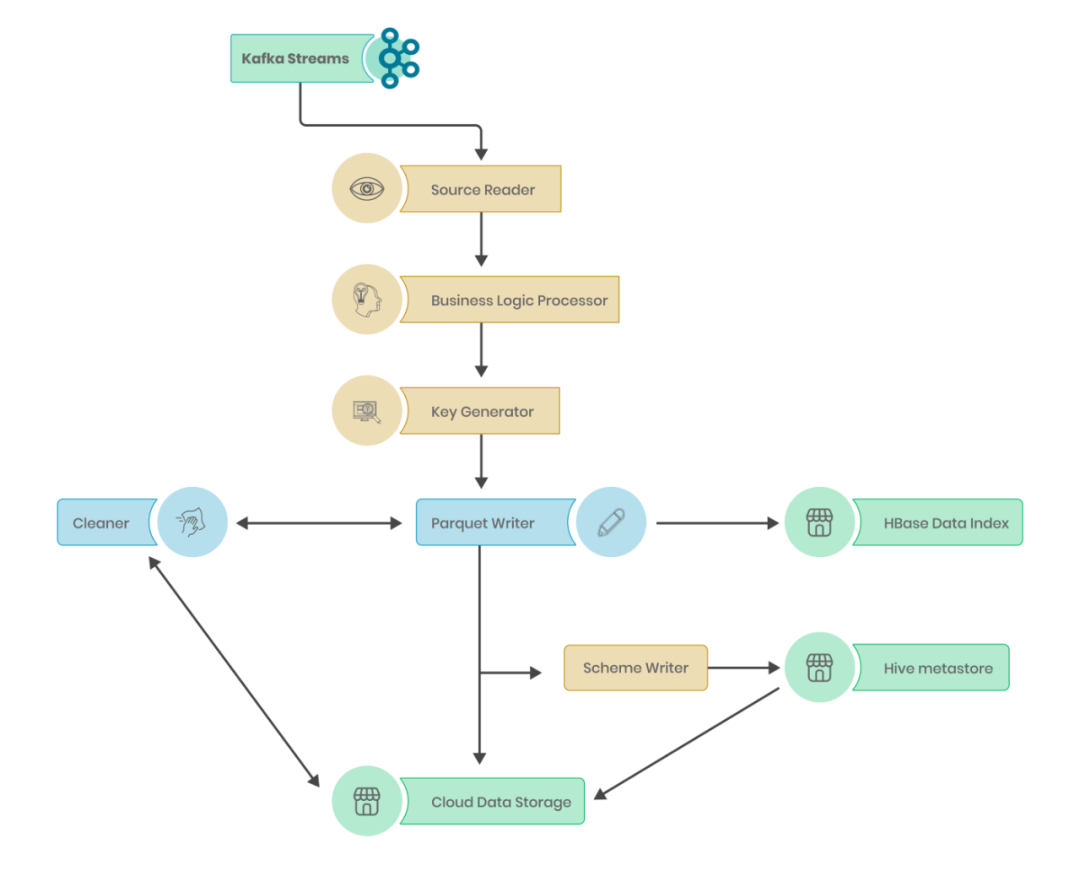
硬核!Apache Hudi Schema演变深度分析与应用
1.场景需求 在医疗场景下,涉及到的业务库有几十个,可能有上万张表要做实时入湖,其中还有某些库的表结构修改操作是通过业务人员在网页手工实现,自由度较高,导致整体上存在非常多的新增列,删除列,改列名的情况。由于Apache Hudi 0.9.0 版本到 0.11.0 版本之间只支持有限的schema变更,即新增列到尾部的情况,且用户对数据质量要求较高,导致了非常高的维护成本。每次删除列和改...

使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的。遵循的基本原则之一是文件的“一次写入多次读取”访问模型。这对于处理海量数据非常有用,如数百GB到TB的数据。但是在构建分析数据湖时,更新数据并不罕见。根据不同场景,这些更新频率可能是每小时一次,甚至可能是每天或每周一次。另外可能还需要在最新视图、包含所有更新的历史视图甚至仅是最新增量视....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache hudi相关内容
- Apache hudi lakehouse
- hudi Apache
- Apache hudi s3
- Apache hudi最佳实践
- Apache hudi架构
- Apache hudi cdc
- Apache hudi构建管道
- Apache hudi管道
- Apache hudi存储
- Apache hudi场景
- Apache hudi索引分析
- Apache hudi索引
- hudi Apache索引分析
- Apache hudi deltalake
- Apache hudi示例
- 数据湖Apache hudi
- Apache hudi zeppelin
- Apache hudi集成
- Apache hudi应用场景
- 实战Apache hudi
- 实战datadog监控Apache hudi
- Apache hudi事务
- Apache hudi大规模数据湖
- Apache hudi数据湖
- Apache hudi构建数据湖
- Apache hudi迁移机制
- Apache hudi异步compaction
- Apache hudi异步部署
- Apache hudi异步
- Apache hudi amazon emr
Apache更多hudi相关
- Apache hudi运行
- Apache hudi功能
- 技术Apache hudi
- 查询Apache hudi
- Apache hudi方案
- Apache hudi构建lakehouse
- Apache hudi实时数据湖
- Apache hudi数据湖实践
- Apache hudi构建实时数据湖
- Apache pulsar hudi构建lakehouse方案
- Apache hudi平台
- Apache hudi概念
- Apache hudi流批一体实践
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi实战
- Apache hudi清理
- Apache hudi aws
- Apache hudi湖仓一体
- Apache hudi流批一体
- Apache hudi数据集
- Apache hudi构建平台
- Apache hudi类型
- Apache hudi流式
- Apache hudi payload
- Apache hudi流批一体架构
- Apache hudi数据湖平台
- Apache hudi湖仓
- Apache hudi特性
Apache您可能感兴趣
- Apache php7.1
- Apache php
- Apache编译
- Apache php版本
- Apache mysql
- Apache湖仓
- Apache湖仓一体
- Apache架构
- Apache doris
- Apache方法
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache实践
- Apache日志
- Apache应用
- Apache web

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注