
巴别时代使用 Apache Paimon 构建 Streaming Lakehouse 的实践
随着数据湖技术的不断发展,越来越多的企业开始探索如何利用这一新兴技术来优化数据处理流程。Apache Paimon 是一款高性能的数据湖框架,它支持流式处理和批处理,能够为实时数据分析提供强大的支持。本文将分享巴别时代在构建基于 Apache Paimon 的 Streaming Lakehouse 方面的一些探索和实践经验。 Apache Paimon...
Apache Hudi在Linkflow构建实时数据湖的生产实践
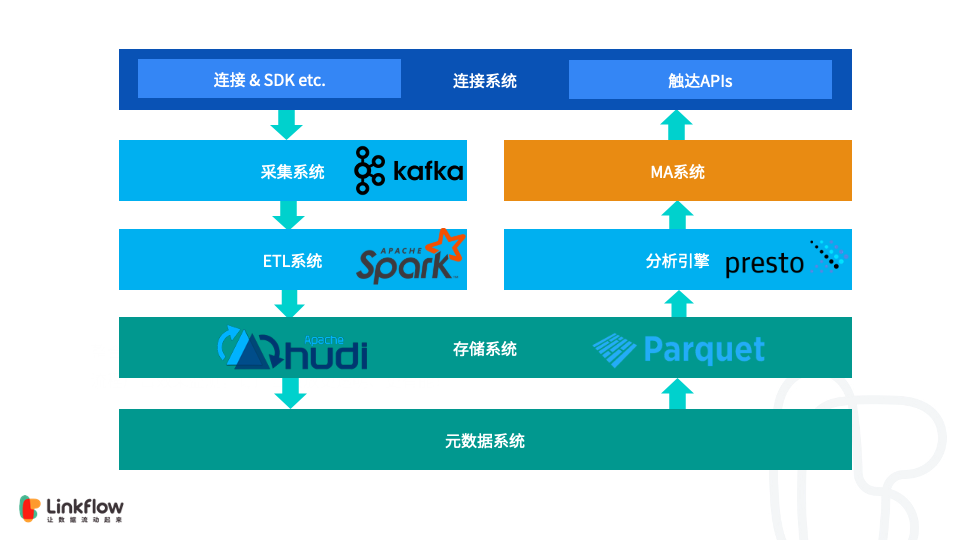
1. 背景 Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又会作为MA (Marketing Automation) 系统的数据源,从而实现对特定人群...
字节跳动基于Apache Hudi构建EB级数据湖实践
接下来将分为场景需求、设计选型、功能支持、性能调优、未来展望五部分介绍Hudi在字节跳动推荐系统中的实践。 ...


万字长文 | 泰康人寿基于 Apache Hudi 构建湖仓一体平台的应用实践
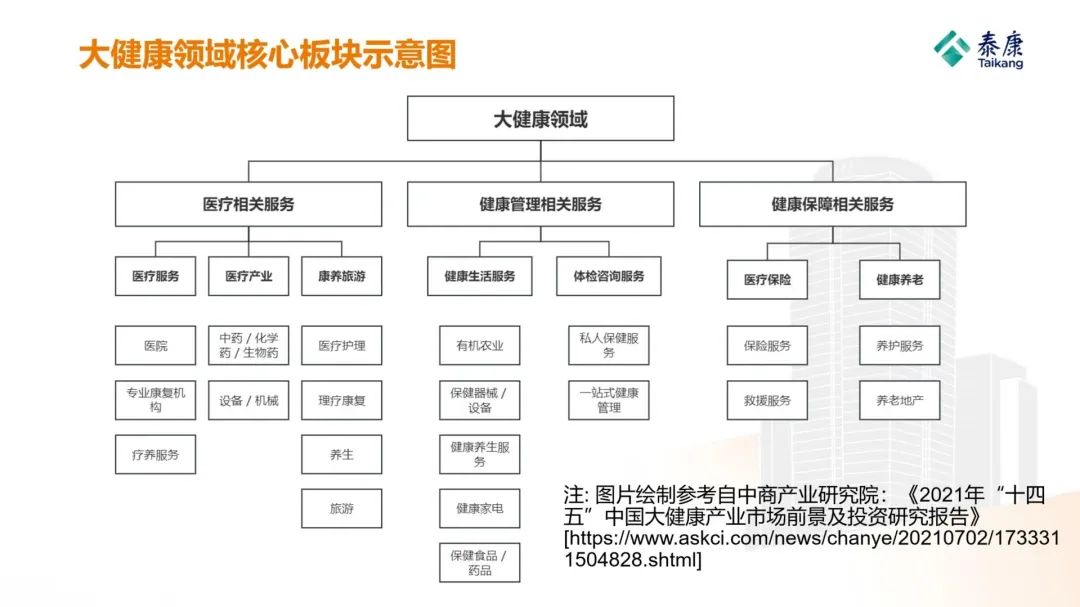
文章贡献者 Authors • 技术指导: 泰康人寿 数据架构资深专家工程师 王可 • 文章作者: 泰康人寿 数据研发工程师 田昕峣 摘要 Abstract 本文详细介绍了泰康人寿基于 Apache Hudi 构建湖仓一体分布式数据处理平台的技术选型方法、整体架构设计与实施、以及针对大健康领域的领域特征和公司战略对 Apache Hudi 进行的功能扩展与实施的详...
Apache Hudi在信息服务行业构建流批一体的实践
个人介绍 李昂 高级数据研发工程师 Apache Doris & Hudi Contributor 业务背景 部门成立早期, 为了应对业务的快速增长, 数仓架构采用了最直接的Lambda架构 1. 对数据新鲜度要求不高的数据, 采用离线数仓做维度建模, 采用每小时调度binlog+每日主键归并的方式实现T+1数据更新 2. 对数据时效性要...

AnalyticDB基于Apache Hudi构建低成本Lakehouse实践
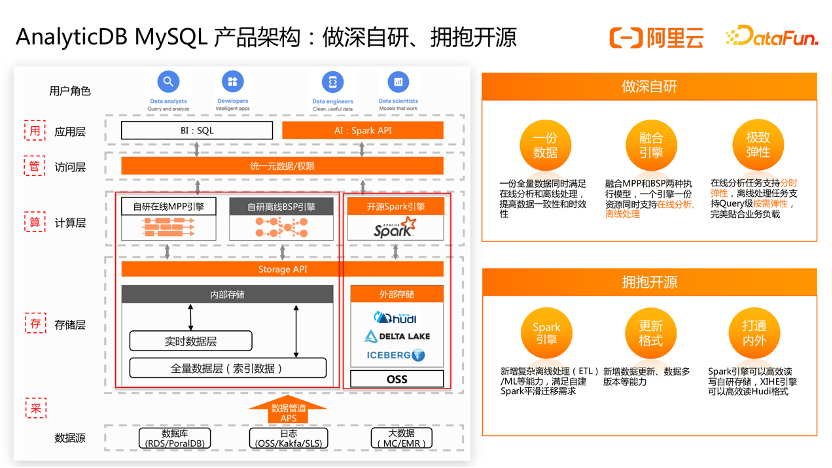
1. AnalyticDB MySQL产品架构首先介绍下 AnalyticDB MySQL(下简称ADB)产品架构, ADB湖仓版产品架构包含自研和开源两部分。ADB湖仓版在数据全链路的「采存算管用」5 大方面都进行了全面升级和建设。在「采集」方面,我们推出了数据管道 APS 功能,可以一键低成本接入数据库、日志、大数据中的数据,解决数据入湖仓的问题。在「存储」方面,我们除了内置Hudi /De....
Uber基于Apache Hudi构建PB级数据湖实践
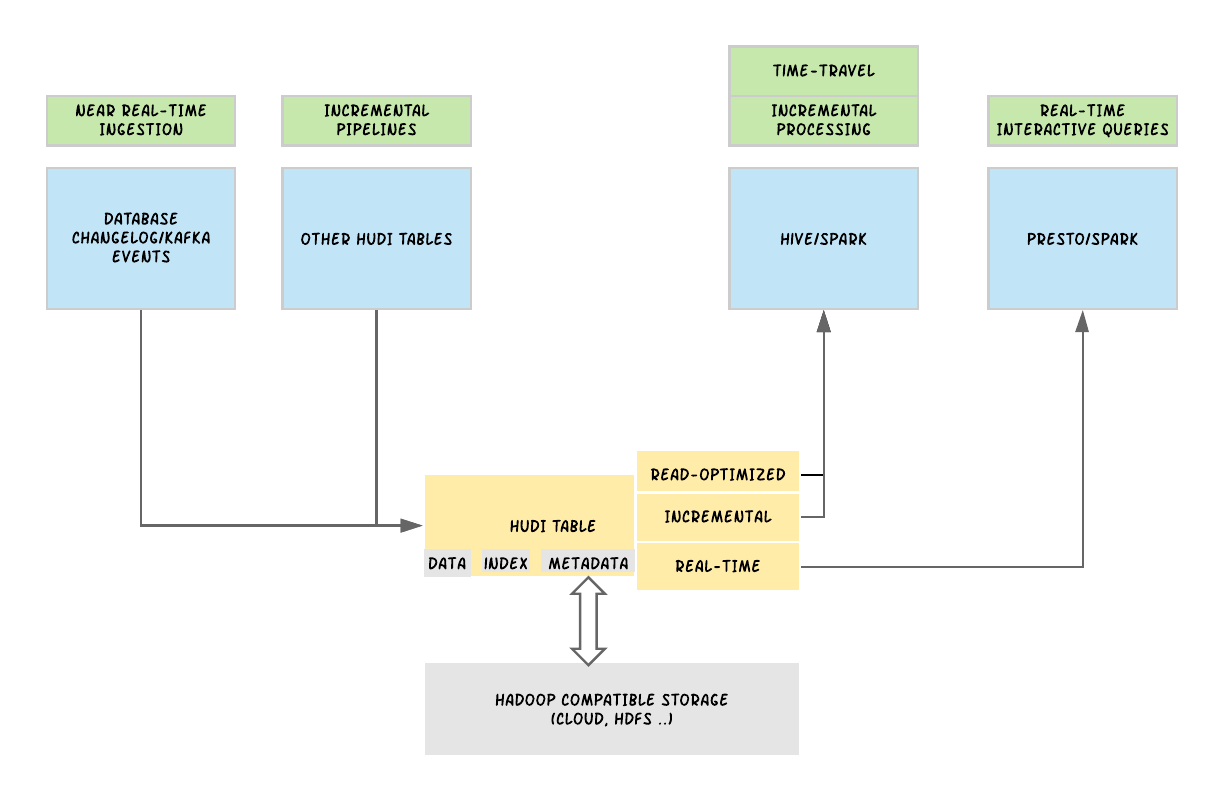
1. 引言从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全、无缝的运输和交付体验需要可靠、高性能的大规模数据存储和分析。2016年,Uber开发了增量处理框架Apache Hudi,以低延迟和高效率为关键业务数据管道赋能。一年后,我们开源了该解决方案,以使得其他有需要的组织也可以利用Hudi的优势。接着在2019年,我们履行承诺,进一步将其捐赠给了Apache Software....
Apache Hudi 在 B 站构建实时数据湖的实践
本文作者喻兆靖,介绍了为什么 B 站选择 Flink + Hudi 的数据湖技术方案,以及针对其做出的优化。主要内容为:传统离线数仓痛点数据湖技术方案Hudi 任务稳定性保障数据入湖实践增量数据湖平台收益社区贡献未来的发展与思考GitHub 地址 https://github.com/apache/flink欢迎大家给 Flink 点赞送 star~一、传统离线数仓痛点1. 痛点之前 B 站数仓....

首发|《Apache Flink 年度最佳实践》,揭秘一线大厂实时平台构建实践
点击免费下载《Apache Flink 年度最佳实践》>>> 《Apache Flink 年度最佳实践》公开下载啦!首次一次性公布来自B站、美团点评、小米、快手、菜鸟、Lyft、Netflix 等精彩内容,9篇深度文章揭秘一线大厂实时平台构建实践。不容错过的精品电子书,大数据工程师必读实战“真经”! Flink 作为业界公认为最好的流计算引擎,不仅仅局限于做流处理,而是一...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache实践相关内容
- Apache湖仓一体实践
- Apache湖仓实践
- 小米Apache paimon流式实践
- Apache paimon湖仓实践
- Apache流式实践
- Apache paimon实践
- elasticsearch Apache实践
- Apache构建lakehouse实践
- Apache lakehouse实践
- Apache streaming实践
- Apache集群实践
- Apache meetup实践
- 科技Apache实践
- 阿里云Apache实践
- Apache iotdb iot实践
- 实践Apache
- 阿里云selectdb内核Apache实践
- 内核Apache doris实践
- selectdb Apache实践
- Apache实践应用
- 离线Apache实践
- Apache场景实践
- 查询内核Apache实践
- Apache构建数据湖实践
- Apache生产实践
- Apache hudi实践
- Apache hudi构建实践
- 快手Apache实践
- 字节跳动Apache实践
- Apache平台实践
Apache更多实践相关
Apache您可能感兴趣
- Apache meetup
- Apache阿里云
- Apache doris
- Apache教程
- Apache配置
- Apache技术
- Apache数据库
- Apache php7.1
- Apache php
- Apache编译
- Apache flink
- Apache rocketmq
- Apache安装
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache日志
- Apache应用
- Apache web

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注