
构建高可用性Apache Kafka集群:从理论到实践
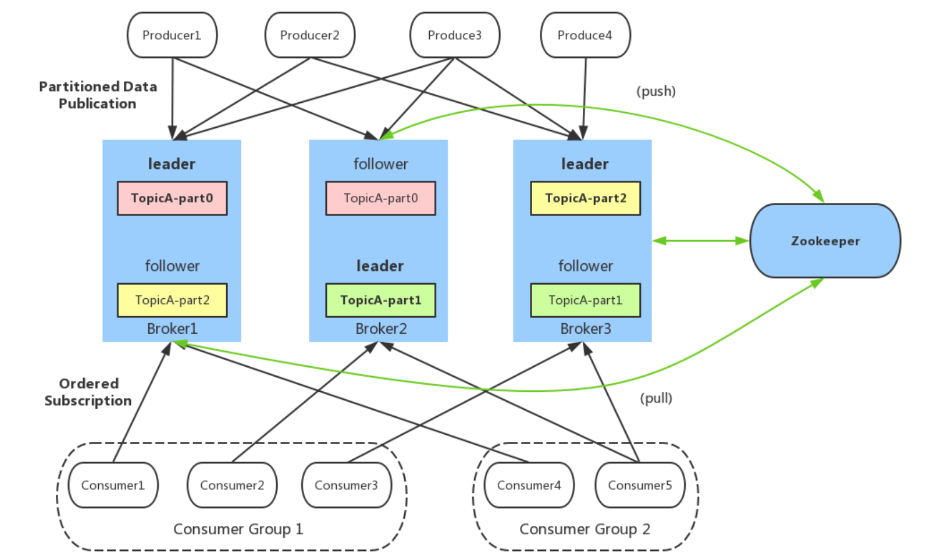
引言 随着大数据时代的到来,数据传输与处理的需求日益增长。Apache Kafka作为一个高性能的消息队列服务,因其出色的吞吐量、可扩展性和容错能力而受到广泛欢迎。然而,在构建大规模生产环境下的Kafka集群时,保证其高可用性是至关重要的。本文将从个人实践经验出发,详细介绍如何构建一个高可用性的Kafka集群,包...
构建高性能Web服务器:Nginx vs Apache
在构建高性能Web服务器的道路上,选择适合的Web服务器软件是至关重要的一步。Nginx和Apache作为两大主流Web服务器软件,各自拥有独特的优势和特点。本文将围绕Nginx和Apache的性能、特点以及适用场景进行详细对比,以帮助读者在构建高性能Web服务器时做出明智的选择。 一、Nginx:轻量级、高并发处理能力的代表 Nginx以...
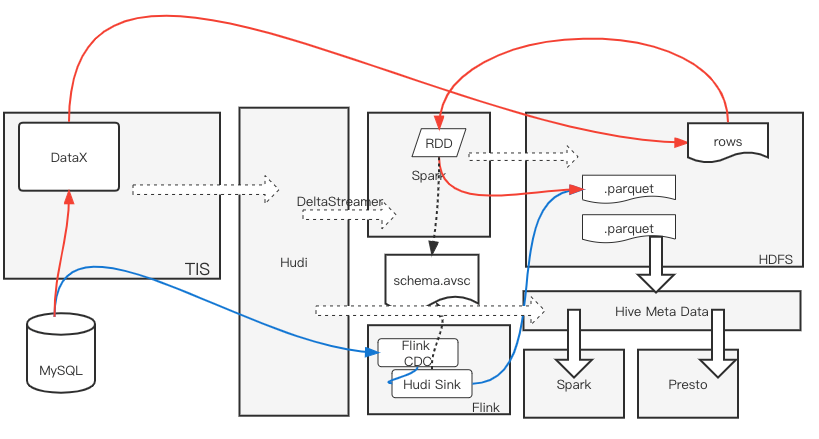
基于TIS构建Apache Hudi千表入湖方案
拥抱数据湖 随着大数据时代的到来,数据量动辄PB级,因此亟需一种低成本、高稳定性的实时数仓解决方案来支持海量数据的OLAP查询需求,Apache Hudi[1]应运而生。Hudi借助与存放在廉价的分布式文件系统之中列式存储文件,并将其元数据信息存放在Hive元数据库中与传统查询引擎Hive、Presto、Spark等整合,完美地实现了计算与存储的分离。Hudi数据湖方案比传统的Hive数...
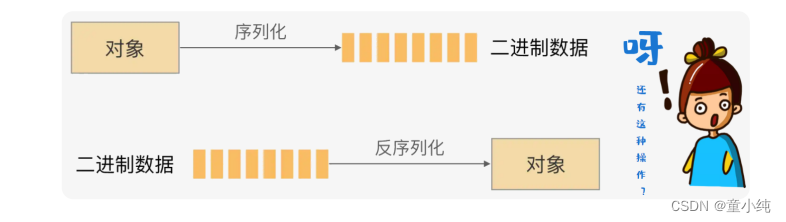
IO流【Java对象的序列化和反序列化、File类在IO中的作用、装饰器模式构建IO流体系、Apache commons-io工具包的使用】(四)-全面详解(学习总结---从入门到深化)
Java对象的序列化和反序列化 序列化和反序列化是什么当两个进程远程通信时,彼此可以发送各种类型的数据。 无论是何 种类型的数据,都会以二进制序列的形式在网络上传送。比如,我 们可以通过http协议发送字符串信息;我们也可以在网络上直接发 送Java对象。发送方需要把这个Java对象转换为字节序列,才能在 网络上传送;接收方则需要把字节序列再恢复为Java对象才能正常 读取。 把Java对象转换....
从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学
从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学 效果展示: 1.Apache jena SPARQL endpoint及推理 在上一篇我们学习了如何利用 D2RQ 来开启 endpoint 服务,但它有两个缺点: 不支持直接将 RDF 数据通过 endpoint 发布到网...
![从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学](https://ucc.alicdn.com/fnj5anauszhew_20230711_744056c6bf96451e849dc19c2c11fcc8.jpeg)
构建可扩展的消息系统:Apache Pulsar和NATS的比较
消息系统在现代分布式应用程序中扮演着至关重要的角色,它们用于实现异步通信、事件驱动架构和可靠数据传输。在本篇文章中,我们将探讨两个流行的消息系统:Apache Pulsar和NATS,并比较它们的特点、性能和可扩展性。我们将研究它们的架构、部署方式以及如何使用它们来构建可靠和高性能的消息传递系统。 Apache Pulsar简介:Apach...
5月9日云栖精选夜读 | 5分钟从零构建第一个 Apache Flink 应用
点击订阅云栖夜读日刊,专业的技术干货,不容错过! 阿里专家原创好文 1.5分钟从零构建第一个 Apache Flink 应用 本刊开篇文章中我们将从零开始,教您如何构建第一个Apache Flink (以下简称Flink)应用程序。 开发环境准备 Flink 可以运行在 Linux, Max OS X, 或者是 Windows 上。阅读更多》》 2.蚂蚁金服开源的机器学习工具 SQLFlow,有....
5分钟从零构建第一个 Apache Flink 应用
作者:伍翀 在本文中,我们将从零开始,教您如何构建第一个Apache Flink (以下简称Flink)应用程序。 开发环境准备 Flink 可以运行在 Linux, Max OS X, 或者是 Windows 上。为了开发 Flink 应用程序,在本地机器上需要有 Java 8.x 和 maven 环境。 如果有 Java 8 环境,运行下面的命令会输出如下版本信息: $ java -vers....
阿里云ECS构建大数据平台实践-基于Apache Hadoop
0. 项目背景 基于阿里云ECS云服务器进行搭建私有的大数据平台,采用Apache Hadoop生态,为大数据提供存储及处理。 1. 购买ECS云服务器实例 在这里,因为实验需要3个节点,所以我们购买3台ECS实例。 2. 远程登录服务器,进行基础环境的配置。 # 工欲善其事,必先利其器 # 前提准备 # 安装系统命令 yum -y install wget vim ntpdate net-...
源代码构建Apache反向代理(包括SSL配置)
由rpm构建的apache是适合大多数场合的应用,它包含了大多数的模块,而我们只是用它去构建反向代理,过多大模块反而不好,影响了性能,所以我们选择了针对性的源代码编译,让apache去适应我们的平台。 下载源代码: wget http://mirrors.cnnic.cn/apache/httpd/httpd-2.2.25.tar.gz 解压 tar zxvf httpd-2.2.25....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache构建相关内容
- Apache kafka构建
- Apache paimon构建
- Apache构建lakehouse
- Apache构建流程
- Apache kylin构建
- Apache kylin流式构建
- Apache cube构建
- Apache增量cube构建
- Apache kylin增量构建
- Apache增量构建
- Apache kylin构建cube
- Apache构建分析
- Apache构建湖仓
- Apache hudi构建
- Apache构建数据湖
- Apache构建实时数据湖
- Apache构建方案
- Apache构建平台
- Apache azure构建
- Apache构建流式
- apachedoris案例集Apache构建
- Apache maven构建
- Apache构建数据中台
- Apache平台构建
- 构建Apache web服务器
- Apache kylin权威指南构建
Apache您可能感兴趣
- Apache实战指南
- Apache湖仓一体
- Apache场景
- Apache doris
- Apache解决方案
- Apache数据
- Apache版本
- Apache实践
- Apache榜单
- Apache seata
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache应用

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注