
org.apache.catalina.connector.ClientAbortException: java.io.IOException: 断开的管道
当把项目Nginx作负载均衡时,有些时间较长的请求,Tomcat就报如下错误: org.apache.catalina.connector.ClientAbortException: java.io.IOException: 断开的管道 at org.apache.catalina.connector.OutputBuffer.realWriteBytes(OutputBuffer. a...
使用Apache Hudi和Debezium构建健壮的CDC管道
一篇在Bangalore Hadoop Meetup上分享的使用Apache Hudi和Debezium构建CDC管道,分享者是Apache Hudi社区活跃贡献者Pratyaksh。 ...

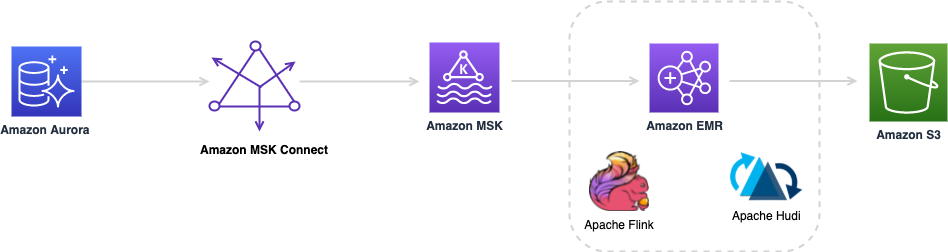
使用 Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
近年来出现了从单体架构向微服务架构的转变。微服务架构使应用程序更容易扩展和更快地开发,支持创新并加快新功能上线时间。但是这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难。为了获得更深入和更丰富的见解,企业应该将来自不同孤岛的所有数据集中到一个地方。AWS 提供复制工具,例如 AWS Database Migration Service (AWS DMS),用于将数据更改从各种源数据库....
Apache Kafka - 构建数据管道 Kafka Connect
概述Kafka Connect 是一个工具,它可以帮助我们将数据从一个地方传输到另一个地方。比如说,你有一个网站,你想要将用户的数据传输到另一个地方进行分析,那么你可以使用 Kafka Connect 来完成这个任务。Kafka Connect 的使用非常简单。它有两个主要的概念:source 和 sink。Source 是从数据源读取数据的组件,sink 是将数据写入目标系统的组件。使用 Ka....

基于Apache Hudi和Debezium构建CDC入湖管道
1. 背景当想要对来自事务数据库(如 Postgres 或 MySQL)的数据执行分析时,通常需要通过称为更改数据捕获 CDC的过程将此数据引入数据仓库或数据湖等 OLAP 系统。 Debezium 是一种流行的工具,它使 CDC 变得简单,其提供了一种通过读取更改日志来捕获数据库中行级更改的方法,通过这种方式 Debezium 可以避免增加数据库上的 CPU 负载,并确保捕获包括删除在内的所有....

Apache中如果不在对齐过程中阻塞已收到barrier的数据管道,会发生什么?
Apache中如果不在对齐过程中阻塞已收到barrier的数据管道,会发生什么?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache管道相关内容
Apache您可能感兴趣
- Apache金融
- Apache场景
- Apache olap
- Apache资源
- Apache引擎
- Apache查询
- Apache doris
- Apache elasticsearch
- Apache方案
- Apache分析
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache实践

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注