
连接外部Hive Metastore Service
EMR Serverless Spark支持连接外部Hive Metastore服务,您可以便捷地访问存储在Hive Metastore中的数据。本文将介绍如何在EMR Serverless Spark中配置和连接外部Hive Metastore服务,以便在工作环境中高效管理和利用数据资源。
Dataphin功能Tips系列(48)-如何根据Hive SQL/Spark SQL的任务优先级指定YARN资源队列
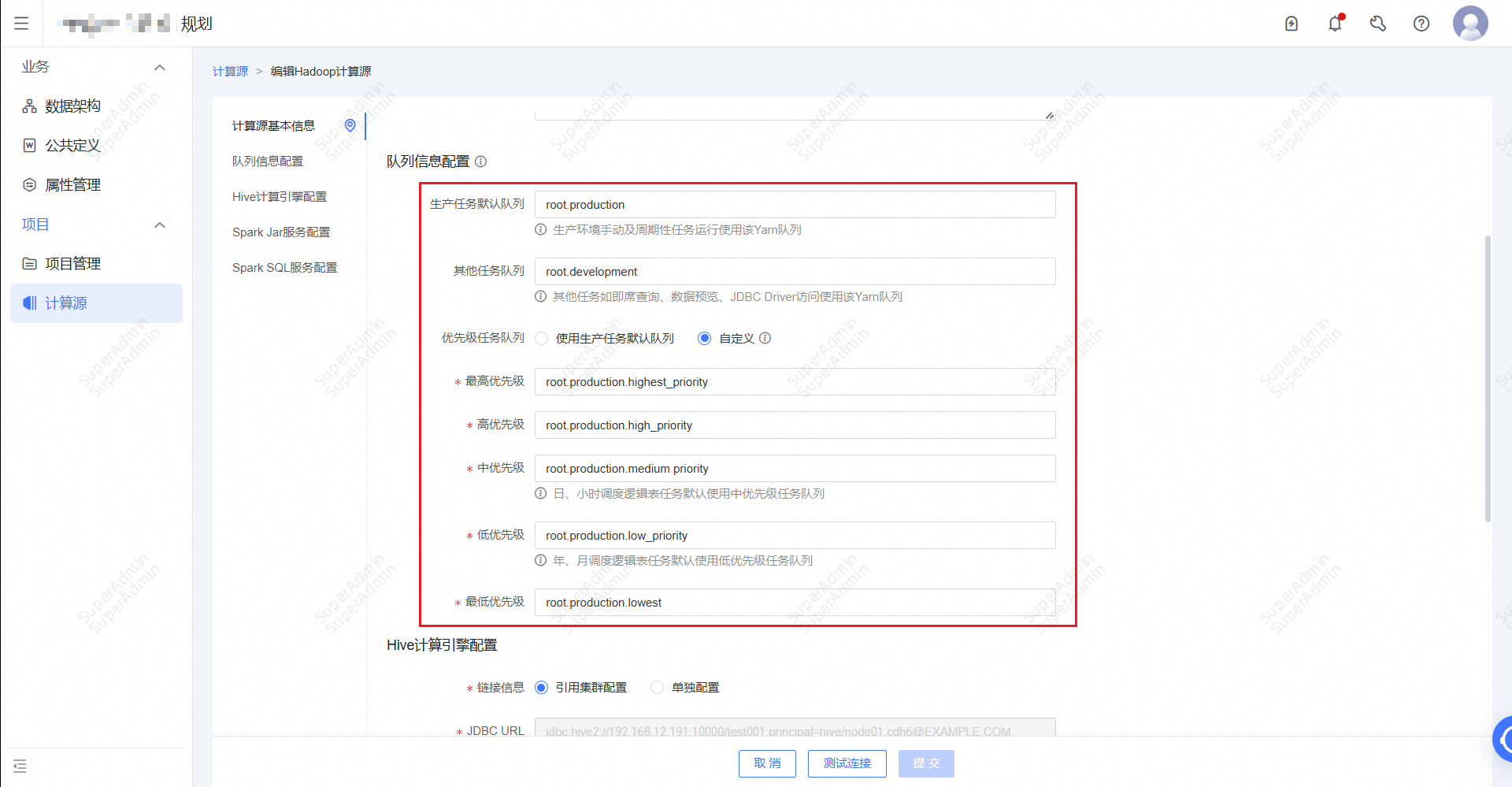
一、场景 客户A需要对生产和开发环境的Hive SQL/Spark SQL根据任务优先级指定YARN资源队列,提高任务执行效率和资源利用率,在Dataphin上如何实现? 二、解决方案及功能 Dataphin支持根据任务优先级指定YARN资源队列 ①【计算源-队列信息配置】配置资源队列,具体可以联系Hadoop的运维团队或者是从yarn-site.xml中获取资源...
基于云服务器的数仓搭建-hive/spark安装
mysql本地安装 安装流程(内存占用200M,升至2.1G) # 将资料里mysql文件夹及里面所有内容上传到/opt/software/mysql目录下 mkdir /opt/software/mysql cd /opt/software/mysql/ # 待上传文件 ins...

实时计算 Flink版产品使用问题之同步到Hudi的数据是否可以被Hive或Spark直接读取
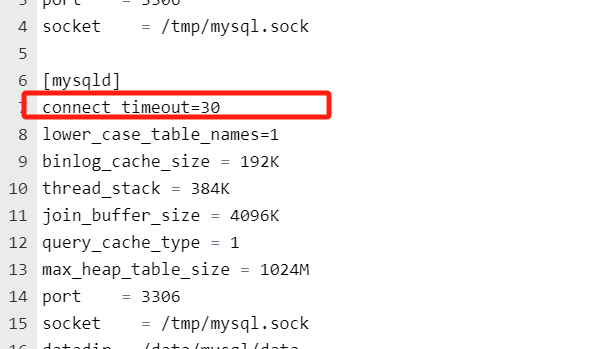
问题一:Flink CDC这个应该在哪里配? Flink CDC这个应该在哪里配?mysql 的超时我已经改成30s了 参考答案: 要么找DBA改一下,要么自己去看有没有参数改,我们是10分钟,有的...
大数据计算MaxCompute 执行 Hive Sql 时,用的什么引擎啊,是Spark 吗?
大数据计算MaxCompute 执行 Hive Sql 时,用的什么引擎啊,是Spark 吗?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC同步到hudi 可以直接读取hudi 的数据吗 例如用hive 或者spark?
Flink CDC写入了hive 后,hive是spark也不能直接对接页面即时查询。 后续怎么办?
Flink CDC写入了hive 后,hive是spark 也不能直接对接页面即时查询,要实时的出数据在页面展现吗?
[AIGC ~大数据] 深入理解Hadoop、HDFS、Hive和Spark:Java大师的大数据研究之旅
作为一位Java大师,我始终追求着技术的边界,最近我将目光聚焦在大数据领域。在这个充满机遇和挑战的领域中,我深入研究了Hadoop、HDFS、Hive和Spark等关键技术。本篇博客将从"是什么"、"为什么"和"怎么办"三个角度,系统地介绍这些技术。是什么?HadoopHadoop是一个开源的分布式计算框架,它能够高效地处理大规模数据集。它的核心是分布式文件系统HDFS和分布式计算模型MapRe....
手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark
引言大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。1.第一章 综合实战概述数据管理平台(Data ManagementPlatform,简称DMP),能够为广告投放提供人群标签进行受众精准定向,并通过投放数据建立用户画像,进行人群标签的管理以及再投放。各大互联网公司都有自己的DMP平台,用户广告精准投....

干翻Hadoop系列文章【02】:Hadoop、Hive、Spark的区别和联系
第一章:Hadoop和Hive以及Spark的关系是什么?Hadoop和Hive、Spark都是大数据领域的技术栈。一:大数据领域当中以后两个最为核心的问题1:数据怎么存储2:海量数据怎么计算单机系统时代。所有数据都在一个计算机上进行存储,数据处理任务都是IO密集型,而不是CPU密集型。数据分布式存储大数据时代 ,海量数据导致我们一台数据服务存不下。这样的话,我们需要一一直加机器进行分布式存储。....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache sparkhive相关内容
- apache spark jdbc hive
- 产品hive apache spark
- apache spark hive字段
- hive引擎apache spark
- apache spark hive查询
- apache spark hive设置
- apache spark hudi hive
- apache spark hive版本
- emr hive apache spark
- apache spark hive解决方案
- apache spark hive etl作业
- apache spark hive类
- hive apache spark参数
- apache spark访问hive
- apache spark hive文件
- apache spark集成hive
- hive apache spark安装指南
apache spark您可能感兴趣
- apache spark训练
- apache spark特征
- apache spark实战
- apache spark学习
- apache spark架构
- apache spark性能
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark任务
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark Scala
- apache spark机器学习
- apache spark yarn
- apache spark技术
- apache spark操作
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注