
大数据-155 Apache Druid 架构与原理详解 数据存储 索引服务 压缩机制
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

Apache Hudi索引实现分析(一)之HoodieBloomIndex
1. 介绍 为了加快数据的upsert,Hudi提供了索引机制,现在Hudi内置支持四种索引:HoodieBloomIndex、HoodieGlobalBloomIndex、InMemoryHashIndex和HBaseIndex,下面对Hudi基于BloomFilter索引机制进行分析。 2. 分析 对于所有索引类型的基类HoodieIndex,其包含了如下核心的抽象方...
Apache Hudi索引实现分析(二)之HoodieGlobalBloomIndex
1. 介绍 前面分析了Hudi默认的索引实现HoodieBloomIndex,其是基于分区记录所在文件,即分区路径+recordKey唯一即可,Hudi还提供了HoodieGlobalBloomIndex的实现,即全局索引实现,只需要recordKey唯一即可,下面分析其实现。 2. 分析 HoodieGlobalBloomIndex是HoodieBloomIndex的子...
Apache Hudi索引实现分析(三)之HBaseIndex
1. 介绍 前面分析了基于过滤器的索引,接着分析基于外部存储系统的索引实现:HBaseIndex。对于想自定义实现Index具有一定的借鉴作用。 2. 分析 HBaseIndex也是HoodieIndex的子类实现,其实现了父类的两个核心方法。 // 给输入记录...
精进Hudi系列|Apache Hudi索引实现分析(四)之基于Tree的IndexFileFilter
1. 介绍 前面分析了基于BloomFilter实现的HoodieBloomIndex和HoodieGlobalBloomIndex,以及基于外部存储系统HBase的索引实现,基于BloomFilter的索引会借助IndexFileFilter来粗略过滤出需要比较的文件,Hudi默认使用HoodieBloomIndex和HoodieGlobalBloomIndex,下面分析其实现。 ...
精进Hudi系列|Apache Hudi索引实现分析(五)之基于List的IndexFileFilter
1. 介绍 前面分析了基于Tree的索引过滤器的实现,Hudi来提供了基于List的索引过滤器的实现:ListBasedIndexFileFilter和ListBasedGlobalIndexFileFilter,下面进行分析。 2. 分析 ListBasedIndexFileFilter是 ListBasedGlobalIndexFileFilter的父类,两者实现了I...
超级重磅!Apache Hudi多模索引对查询优化高达30倍
与许多其他事务数据系统一样,索引一直是 Apache Hudi 不可或缺的一部分,并且与普通表格式抽象不同。在这篇博客中,我们讨论了我们如何重新构想索引并在 Apache Hudi 0.11.0 版本中构建新的多模式索引,这是用于 Lakehouse 架构的首创高性能索引子系统,以优化查询和写入事务,尤其是对于大宽表而言。 1. 为什么在 Hudi 中使用多模索引 索引[1]被广...
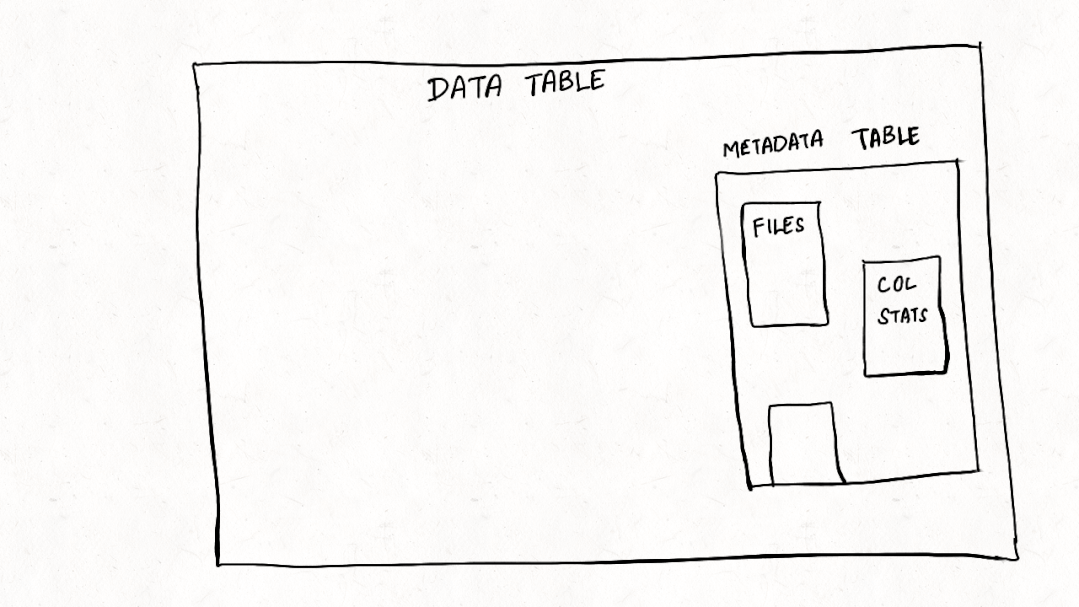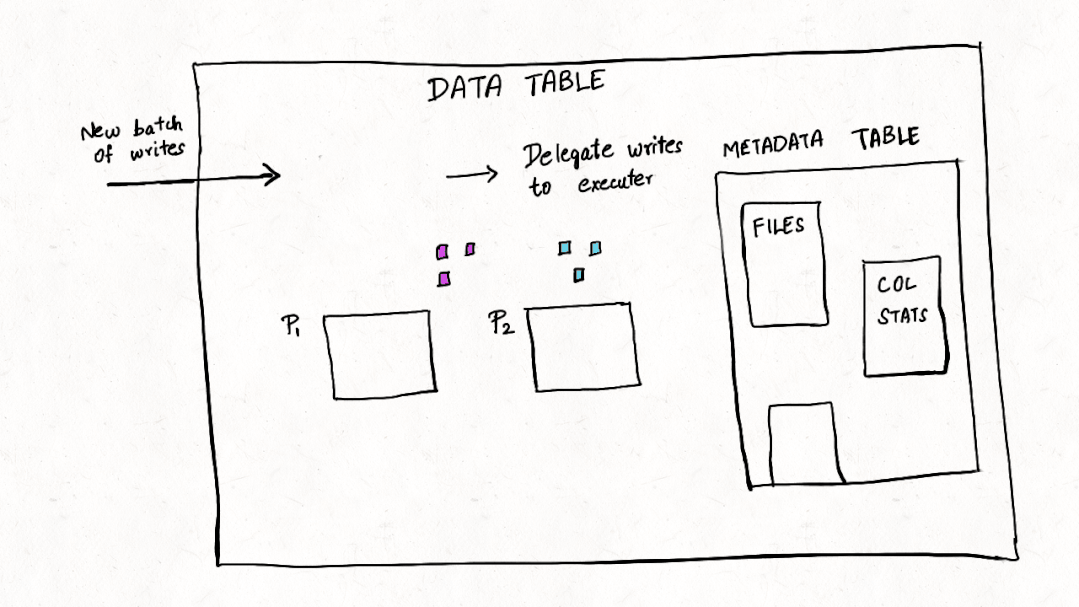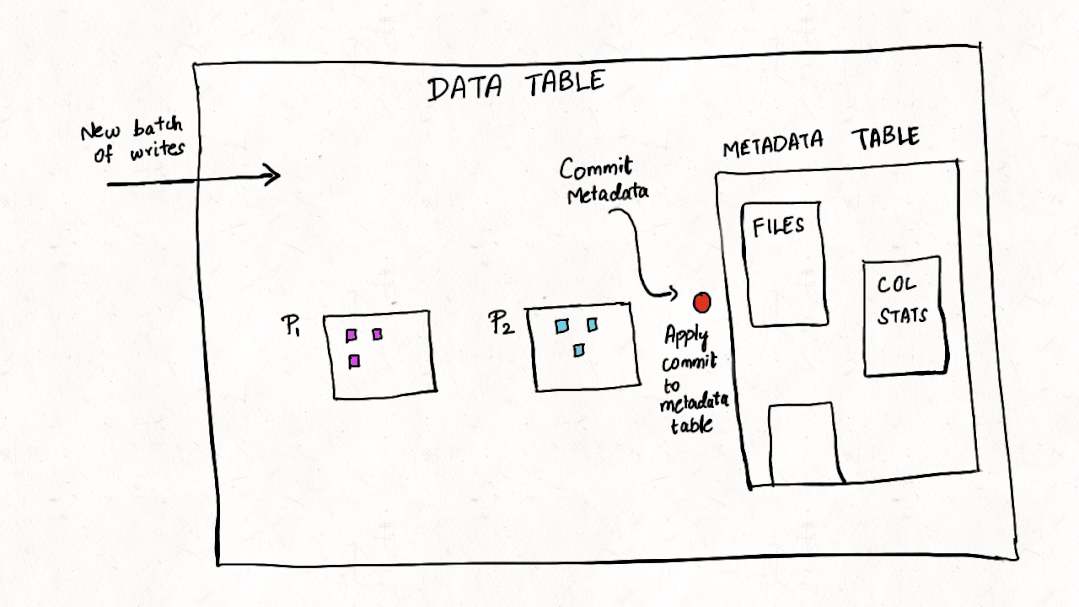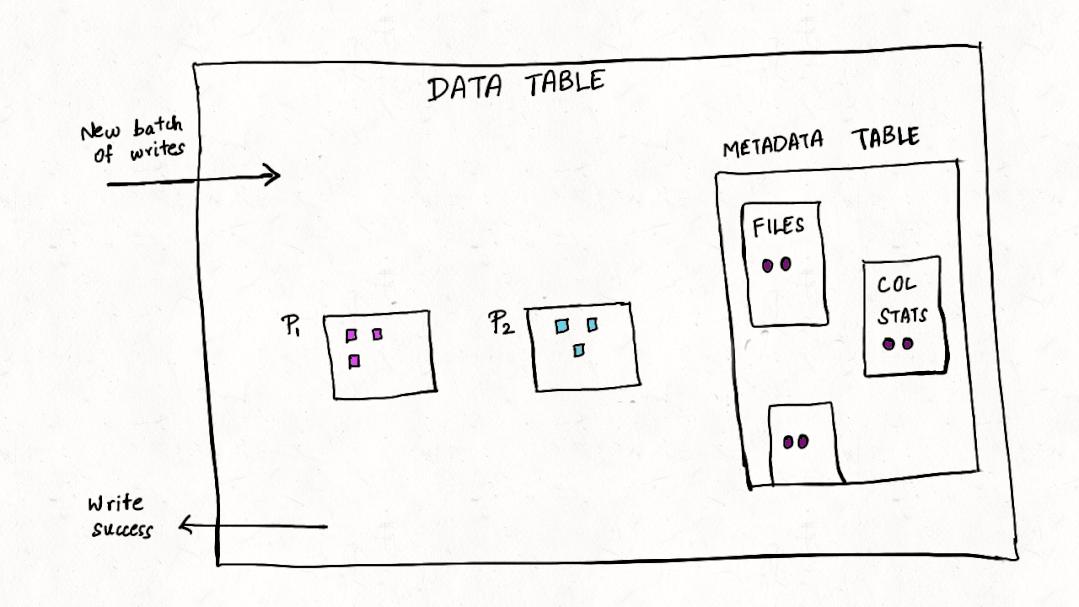
深入理解Apache Hudi异步索引机制
在我们之前的文章中,我们讨论了多模式索引[1]的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能。在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制的设计,类似于 PostgreSQL[2] 和 MySQL[3] 等流行的数据库系统,它支持索引构建而不会阻塞写入。 背景 Apache Hudi 将事务和更新/删除/更改流添...
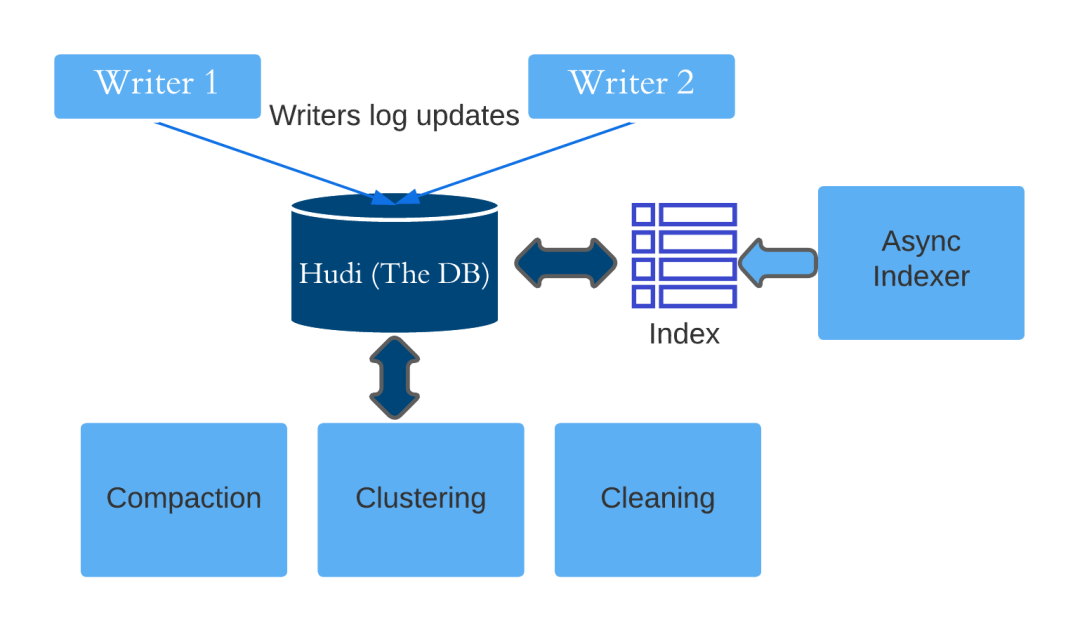
一文聊透Apache Hudi的索引设计与应用
Apache Hudi索引在数据读和写的过程中都有应用。读的过程主要是查询引擎利用MetaDataTable使用索引进行Data Skipping以提高查找速度;写的过程主要应用在upsert写上,即利用索引查找该纪录是新增(I)还是更新(U),以提高写入过程中纪录的打标(tag)速度。 MetaDataTable 目前使能了"hoodie.metadata.enable"后,会...
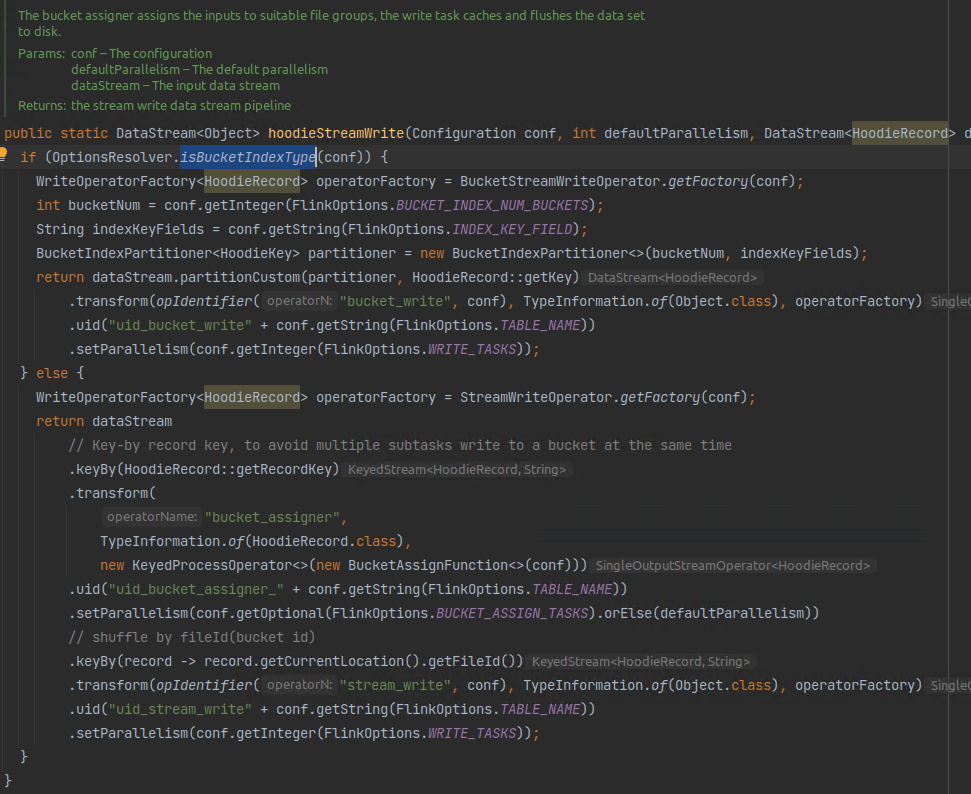
记录级别索引:Apache Hudi 针对大型数据集的超快索引
介绍 索引是一个关键组件,有助于 Hudi 写入端快速更新和删除,并且它在提高查询执行方面也发挥着关键作用。Hudi提供了多种索引类型,包括全局变化的Bloom索引和Simple索引、利用HBase服务的HBase索引、基于哈希的Bucket索引以及通过元数据表实现的多模态索引。索引的选择取决于表大小、分区数据分布或流量模式等因素,其中特定索引可能更适合更简单的操作或更好的性能。用户在为...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache索引相关内容
Apache您可能感兴趣
- Apache湖仓一体
- Apache解决方案
- Apache doris
- Apache场景
- Apache数据
- Apache版本
- Apache实践
- Apache榜单
- Apache seata
- Apache开源项目
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache mysql
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache hudi
- Apache应用

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注