
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
数据湖技术:Hadoop与Spark在大数据处理中的协同作用 在大数据时代,数据湖技术以其灵活性和成本效益成为了企业存储和分析大规模异构数据的首选。Hadoop和Spark作为数据湖技术中的两个核心组件,它们在大数据处理中的协同作用至关重要。本文将探讨Hadoop与Spark的最佳实践,以及如何在实际应用中发挥它们的协同效应。 Hadoop...
数据湖技术:Hadoop与Spark在大数据处理中的协同作用
随着大数据技术的不断发展,数据湖作为一种集中式存储和处理海量数据的架构,越来越受到企业的青睐。Hadoop和Spark作为数据湖技术的两大核心组件,在大数据处理中发挥着不可替代的作用。本文将通过最佳实践的形式,详细探讨Hadoop与Spark在大数据处理中的协同作用,并提供具体的示例代码。 Hadoop,作为一个...
技术好文:Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护//代码效果参考:http://hnjlyzjd.com/xl/wz_25104.html 模式,主要的机器学习API是spark-ml包中的DataFrame-based A...
大数据技术:Hadoop与Spark的对比
一、引言 随着数据量的爆炸性增长,大数据技术成为了处理和分析这些海量数据的关键。Hadoop和Spark作为当前最流行的大数据处理框架,各自具有独特的优势和适用场景。本文将对Hadoop和Spark进行详细的对比,帮助读者更好地理解两者的异同,以便在实际应用中做出明智的选择。 二、Hadoop概述 Hadoop是一个由Apache基金会开发...
探索大数据技术:Hadoop与Spark的奥秘之旅
在当今这个信息爆炸的时代,大数据已经成为了推动社会进步和企业发展的重要力量。为了更好地利用这些海量的数据资源,大数据技术如Hadoop和Spark应运而生,为我们提供了强大的数据处理和分析能力。本文将带领大家深入探索Hadoop和Spark的技术奥秘,解析它们的工作原理、应用场景以及未来发展趋势。 一、Hadoop:大数据处理...
大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和Hadoop进行分布式计算,以应对大数据挑战...
Hudi数据湖技术引领大数据新风口(三)解决spark模块依赖冲突
解决spark模块依赖冲突修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:vim /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml在382行的位置,修改如....
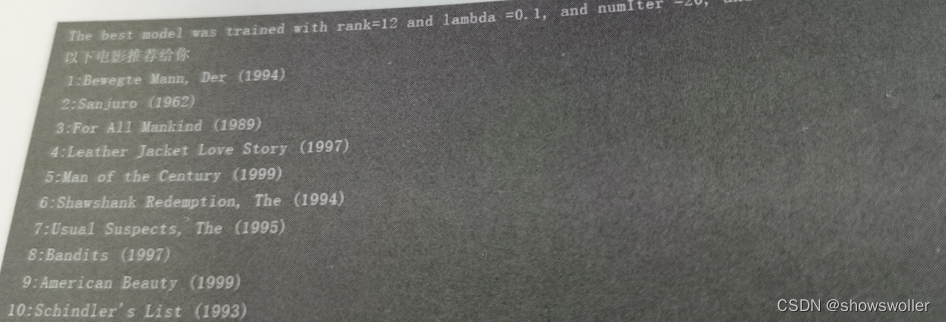
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电影和针对电影推荐用户两种方式。若采用基于用户的推荐模型,则会利用相似用户的评级来计算对某个用户的推....
【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通过样本数据和梯度下降训练模型,找到10个产生比较合理的参数值(a_1到a_10)回归结果如下部分代....

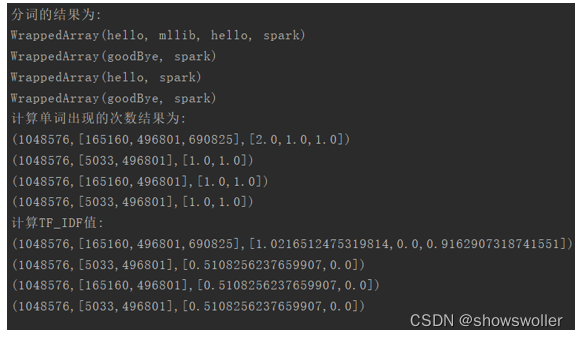
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词出现的次数。它用来度量词对文档的重要程度,TF越大,该词在文档中就越重要。IDF逆向文档频率,是指....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark您可能感兴趣
- apache spark游戏
- apache spark驱动
- apache spark构建
- apache spark应用
- apache spark系统
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark实战
- apache spark yarn
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注