
强化深度学习中使用Dyna-Q算法确定机器人问题中不同规划的学习和策略实战(超详细 附源码)
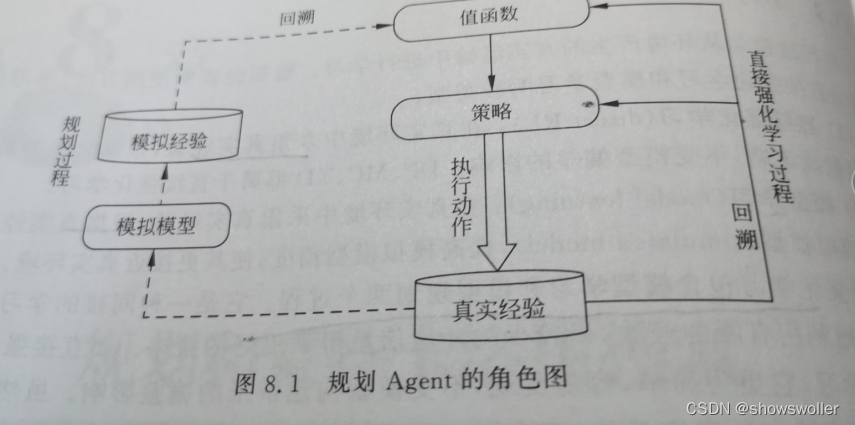
需要源码请点赞关注收藏后评论区留下QQ并且私信~~~一、模型、学习、规划简介1:模型Agent可以通过模型来预测环境并做出反应,这里所说的模型通常指模拟模型,即在给定一个状态和动作时,通过模型可以对下一状态和奖赏做出预测模型通常可以分为分布模型和样本模型两种类型分布模型:该模型可以生成所有可能的结果及其对应的概率分布样本模型:该模型能够从所有可能的情况中产生一个确定的结果从功能上讲,模型是用于模....
深度强化学习中利用Q-Learngin和期望Sarsa算法确定机器人最优策略实战(超详细 附源码)
需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~一、Q-Learning算法Q-Learning算法中动作值函数Q的更新方向是最优动作值函数q,而与Agent所遵循的行为策略无关,在评估动作值函数Q时,更新目标为最优动作值函数q的直接近似,故需要遍历当前状态的所有动作,在所有状态都能被无限次访问的前提下,Q-Learning算法能以1的概率收敛到最优动作值函数和最优策略下图是估算最优策略的....

【智能优化算法-差分进化算法】基于多种交叉策略和变异策略的差分进化算法求解单目标优化问题含Matlab源码
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。个人主页:Matlab科研工作室个人信条:格物致知。更多Matlab仿真内容点击智能优化算法神经网络预测雷达通信 无线传感器信号处理图像处理路径规划元胞自动机无人机1 内容介绍单目标优化,多目标优化和约束优化问题在数学和工程领域普遍存在,且变得越来越复杂.进化计算是求解此类问题的有效方法,近....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多源码相关

智能引擎技术
AI Online Serving,阿里巴巴集团搜推广算法与工程技术的大本营,大数据深度学习时代的创新主场。
+关注