支持 PB 级海量存储,通过列式存储和 ZSTD 压缩降低存储空间占用。支持百TB/天、GB/s的日志数据持续实时写入。支持倒排索引和全文检索,关键词检索、趋势分析等查询秒级响应。
上游通过通用 HTTP API 对接日志采集系统和数据源 Logstash、Filebeat、Fluentbit、Kafka 等,下游通过标准 MySQL 协议和语法对接可视化分析工具,如 Grafana、QuickBI 和 Superset 等。
支持秒级快速增加、删除字段和索引,并提供了半结构化数据类型 VARIANT,可以写入任何 JSON 动态数据并自动识别其中字段名和类型,采用列式存储以便于后续高效分析。
在日志分析、实时数仓等场景中,阿里云 SelectDB 与自建 Elasticsearch(ES)的核心差异体现在技术架构、成本效率、场景适配性等多个维度。
| 自建 ES 方案 | VS | 阿里云 SelectDB 方案 |
写入吞吐低 受限于JVM内存模型与多副本冗余索引机制,叠加后台索引碎片高频合并操作,导致系统吞吐量显著下降、请求响应延迟激增。 | 写入性能 | 写入吞吐高 基于C++无锁架构与SIMD指令级向量化优化,结合单副本零拷贝写入机制及单次时序归并策略,吞吐量提升多倍以上。 |
搜索能力强,分析能力弱 搜索和点查性能高,聚合分析性能低,仅支持单表查询。 | 分析能力 | 多场景性能优异,分析能力强 搜索和点查性能高,聚合分析性能提升多倍,支持丰富的JOIN、湖仓一体等复杂分析能力。 |
存储成本高 行存 + 列存 + 复杂倒排索引,存算一体多副本云盘存储空间。 | 存储成本 | 存储成本低 列存 + 精简倒排索引,存算分离一副本对象存储空间,存储成本大幅降低。 |
部分支持 仅支持动态添加字段。 | 灵活 Schema | 完整支持 支持动态增加字段、删除字段、增加字段索引、删除字段索引、增量构建索引、修改索引名、字段名。 |
生态封闭、使用门槛高 定制的 DSL 学习门槛高,熟悉后仍然要查手册,ES 私有生态相对封闭。 | 开放易用 | 生态开放、简单易用 标准的 SQL 简单易上手,熟悉后可以轻松写,不仅兼容开放的 MySQL 生态,还支持 ES 生态中 Logstash、Filebeat 等日志采集。 |
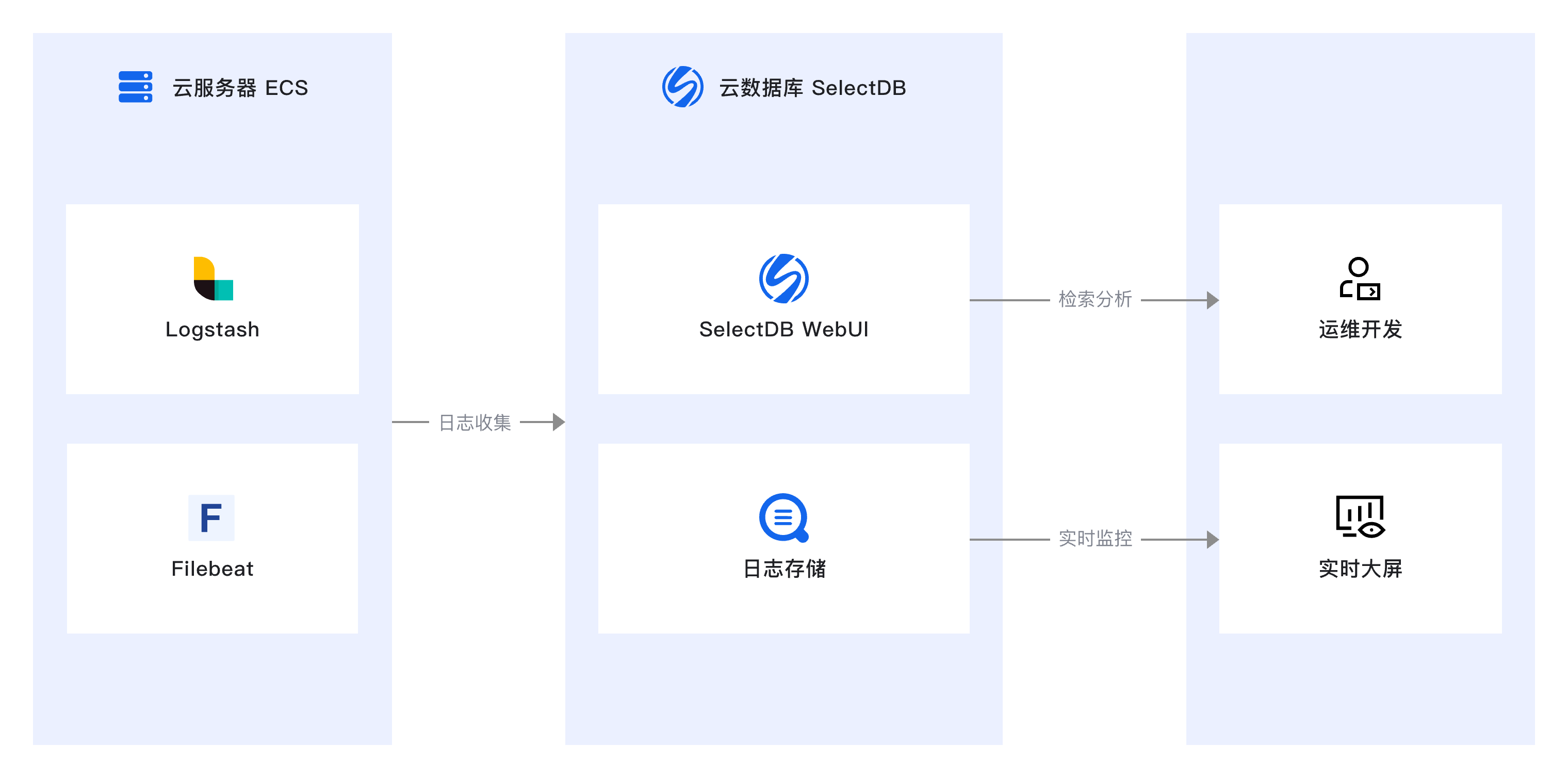
本方案采用两种真实的日志(HTTP Logs 日志和 GitHub events 用户行为日志)作为数据源,下载和安装两种日志采集器(Logstash 和 Filebeat)用于对日志的采集,通过 SelectDB 开放接口把日志存储到 SelectDB 中。SelectDB 通过SIMD 等 CPU 向量化指令提升写入性能,通过列式存储和 ZSTD 压缩降低存储成本,在实现高性能的同时保持很低的成本。其次,SelectDB 的 Light Schema Change 和半结构化数据类型 VARIANT 支持 FlexibleSchema,能够灵活应对日志数据的多样性和复杂性,可以写入任何 JSON 动态数据并自动识别其中字段名和类型,采用列式存储以便于后续高效分析。此外,SelectDB 提供了类似 Kibana Discover 的日志检索分析界面,支持基于时间段、关键字检索以及 SQL 查询的日志分析。

SelectDB 提供强大的日志可观测性,使企业能够实时监控和分析系统及应用程序的运行状态,确保服务的高可用性和稳定性。

SelectDB 在网络安全监控方面发挥着关键作用,通过收集和分析网络活动日志,帮助企业识别潜在的安全威胁和异常行为,从而增强企业的安全防护能力。

SelectDB 具备用户行为分析、用户画像等业务分析能力,使企业能够从日志数据中提取有价值的业务洞察,进而提升业务成果,并推动创新和增长。
本方案是基于开放可控数据湖仓构建的大数据/搜索/ AI 一体化解决方案。通过元数据管理平台 DLF 管理结构化和半/非结构化数据,提供湖仓数据表和文件的安全访问及 IO 加速。支持多引擎对接和平权协同计算,通过 DataWorks 统一开发,并保障大规模任务调度。
在数据驱动决策的时代,一款性能卓越的数据分析引擎不仅能为企业提供高效的数据支撑,同时也解决了传统 OLTP 在数据分析时面临的查询性能瓶颈、数据不一致等挑战。本方案推荐通过 AnalyticDB MySQL + DTS 来解决 MySQL 的数据分析性能问题。

你好,我是AI助理
可以解答问题、推荐解决方案等
